少し前に、最も一般的な名前空間の概要をカバーする記事を書きました。この情報は素晴らしいものであり、ある程度、この知識をどのように活用できるかを推測できると確信しています。物事をそんなに自由なままにしておくのは、通常、私のスタイルではありません。したがって、次の2つの記事では、プリミティブLinuxコンテナーを作成するというレンズを通して、より重要な名前空間のいくつかをデモンストレーションすることに時間を費やします。ある意味で、クライアントサイトでLinuxコンテナーのトラブルシューティングを行うときに使用した手法の経験を書き留めています。そのことを念頭に置いて、特にセキュリティが懸念される場合は、コンテナの基盤から始めます。
Linuxの機能について少し
Linuxシステムのセキュリティには、さまざまな形態があります。この記事の目的のために、私はファイルのパーミッションに関しては主にセキュリティに関心があります。念のため、Linuxシステム上のすべてはある種のファイルであるため、ファイルのアクセス許可は、誤動作する可能性のあるアプリケーションに対する最初の防衛線です。
Linuxがファイル権限を処理する主な方法は、ユーザーの実装によるものです。 。 通常のユーザーがいます Linuxが特権チェックを適用し、スーパーユーザーが存在する ほとんどの(すべてではないにしても)チェックをバイパスします。つまり、元のLinuxモデルはオールオアナッシングでした。
これを回避するために、一部のプログラムバイナリにはset uidがあります。 それらにビットが設定されています。この設定により、プログラムはバイナリを所有するユーザーとして実行できます。 passwd ユーティリティはこの良い例です。すべてのユーザーがシステムでこのユーティリティを実行できます。 shadowと対話するには、システムに対する昇格された特権が必要です。 Linuxシステムのユーザーパスワードのハッシュを格納するファイル。 passwd バイナリには、ある通常のユーザーが別のユーザーのパスワードを変更できないことを確認するチェックが組み込まれています。特にシステム管理者がset uidをオンにした場合、多くのアプリケーションは同じレベルの精査を受けません。 ビット。
Linuxの機能 セキュリティモデルのよりきめ細かいアプリケーションを提供するために作成されました。バイナリをrootとして実行する代わりに、アプリケーションが効果を発揮するために必要な特定の機能のみを適用できます。 Linux Kernel 5.1の時点で、38の機能があります。機能のマニュアルページは実際には非常によく書かれており、各機能について説明しています。
機能セット 機能をスレッドに割り当てる方法です。簡単に言うと、合計5つの機能セットがありますが、この説明では、有効と許可の2つだけが関連しています。
効果的 :カーネルは各特権アクションを検証し、システムコールを許可するか禁止するかを決定します。スレッドまたはファイルに有効がある場合 機能の場合、有効な機能に関連するアクションを実行できます。
許可 :許可された機能はまだアクティブではありません。ただし、プロセスが許可されている 機能とは、プロセス自体がその特権を効果的な特権にエスカレートすることを選択できることを意味します。
特定のプロセスにどのような機能があるかを確認するには、getpcaps ${PID}を実行します。 指図。このコマンドの出力は、Linuxのディストリビューションによって異なります。 RHEL / CentOSでは、機能の全リストが表示されます:
[root@CentOS8 ~]# getpcaps $$
Capabilities for `1304': = cap_chown,cap_dac_override,cap_dac_read_search,cap_fowner,cap_fsetid,cap_kill,cap_setgid,cap_setuid,cap_setpcap,cap_linux_immutable,cap_net_bind_service,cap_net_broadcast,cap_net_admin,cap_net_raw,cap_ipc_lock,cap_ipc_owner,cap_sys_module,cap_sys_rawio,cap_sys_chroot,cap_sys_ptrace,cap_sys_pacct,cap_sys_admin,cap_sys_boot,cap_sys_nice,cap_sys_resource,cap_sys_time,cap_sys_tty_config,cap_mknod,cap_lease,cap_audit_write,cap_audit_control,cap_setfcap,cap_mac_override,cap_mac_admin,cap_syslog,cap_wake_alarm,cap_block_suspend,cap_audit_read,38,39+ep
コマンドman 7 capabilitiesを実行した場合 、これらすべての機能のリストとそれぞれの説明があります。 UbuntuやArchなどの一部のディストリビューションでは、同じコマンドを実行すると、次のようになります。
[root@Arch ~]# getpcaps $$
414429: =ep =の前に空白があります サイン。この空白は、キーワード allと交換可能です。 。ご想像のとおり、これは、システムで利用可能なすべての機能が両方の Eで付与されることを意味します。 効果的でP 許可された機能セット。
何でこれが大切ですか?まず、機能セットはユーザーの名前空間に関連付けられています(これについては以下で説明します)。今のところ、これが意味するのは、各名前空間には、その自身にのみ適用される独自の機能セットがあるということです。 名前空間。 制約付きという名前空間があるとします。 。 制約の可能性があります 見た目 getpcapsで見られるように、すべての適切な機能を備えているように 指図。ただし、制約がある 完全な機能セット(通常のユーザーなど)を持たないプロセスと名前空間によって作成され、制約された 作成プロセスよりも多くの権限をシステムに付与することはできません。
要約すると、機能は名前空間テクノロジーではありませんが、名前空間内のプロセスが実行できる内容と方法を決定する際に連携して機能します。
[次のこともお楽しみいただけます:rootなしのPodmanをroot以外のユーザーとして実行する]
ユーザー名前空間
ユーザー名前空間の作成に取り掛かる前に、この名前空間の目的を簡単に要約します。以前の記事で説明したように、ユーザー名、そして最終的にはユーザー識別番号(UID)は、システムがユーザーとプロセスが許可されていないものにアクセスしないようにするために使用するセキュリティの層の1つです。
ユーザー名前空間の背後にある理論
ユーザー名前空間は、コンテナー(分離されたプロセスのセット)がシステム自体とは異なるアクセス許可のセットを持つための方法です。すべてのコンテナは、新しいユーザー名前空間を作成したユーザーから権限を継承します。たとえば、ほとんどのLinuxシステムでは、通常のユーザーIDは1000以上で始まります。このシリーズの残りの部分では、 container-userという名前のユーザーを使用します。 、次のIDがあります(これらのデモではSELinuxコンテキストは省略されています):
uid=1000(container-user) gid=1000(container-user) groups=1000(container-user) システム管理者によって意図的に制限されていない限り、理論的には、どのユーザーも新しいユーザー名前空間を作成できることに注意してください。ただし、これはシステム自体の管理者からの難読化にはなりません。ユーザー名前空間は階層です。次の図を検討してください:
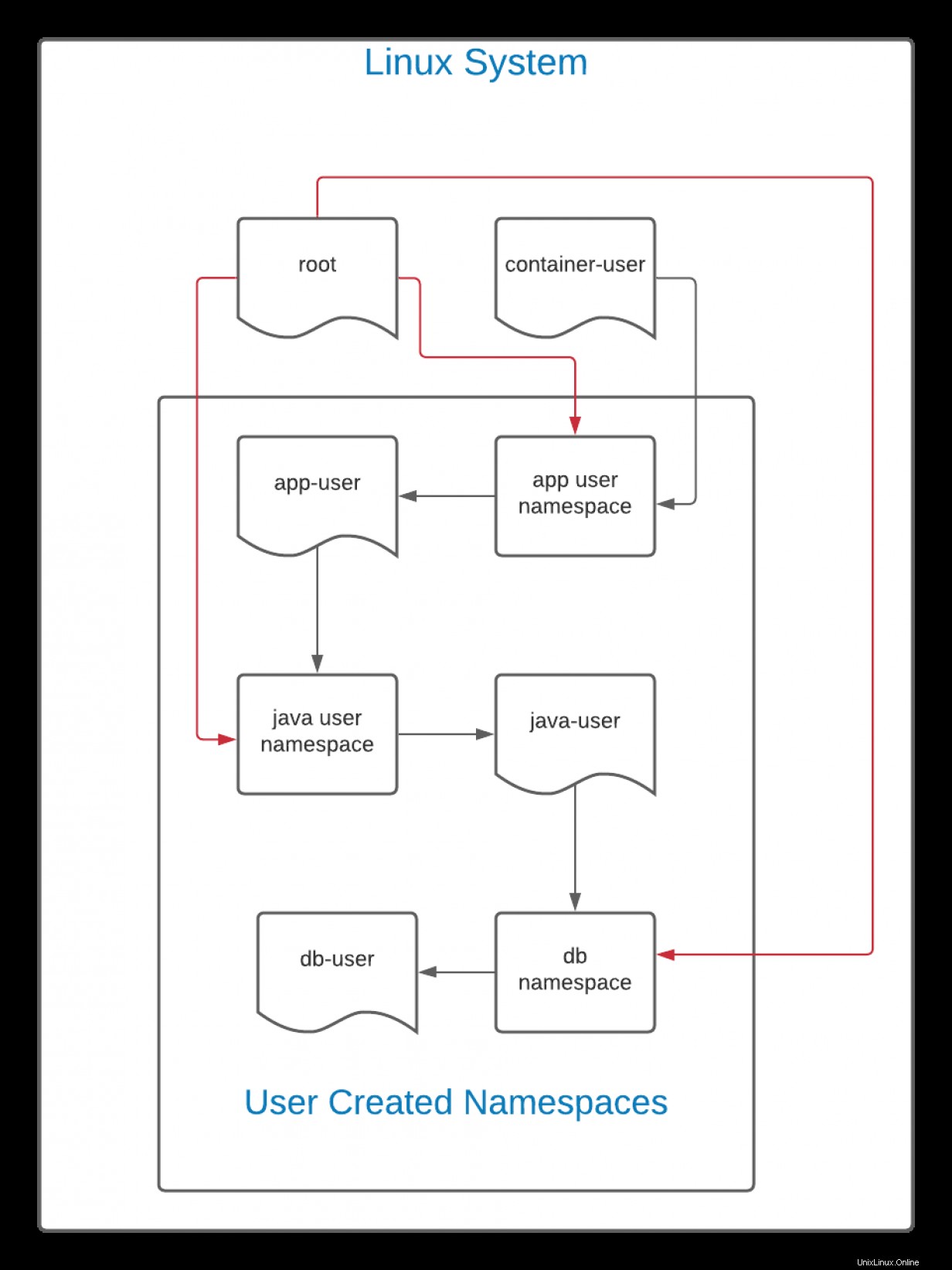
この図の黒い線は、作成の流れを示しています。ユーザーcontainer-user app-userというユーザーの名前空間を作成します 。理論的には、これはWebフロントエンドまたは他のアプリケーションになります。次に、 app-user java-userのユーザー名前空間を作成します 。この名前空間では、 java-user db-userの名前空間を作成します 。
これは階層であるため、 container-user UIDから生成された名前空間のいずれかによって作成されたすべてのファイルを表示してアクセスできます。同様に、ルート Linuxシステムのユーザーは、すべてを表示して操作できます。 container-userによって作成されたファイルを含むシステム上のファイル 、ルート ユーザー(赤い線で表されている)は、すべての名前空間に対する完全な権限を持つことができます。
ただし、その逆は当てはまりません。 db-user この場合、ユーザーはその上にあるものを見たり操作したりすることはできません。 IDマッピングが同じままである場合(デフォルトのポリシー)、 app-user 、 java-user 、および db-user すべて同じUIDを持っています。ただし、それらは同じUIDを共有しますが、 db-user java-userと対話できません 、 app-userとやり取りできません 、など。
ユーザー名前空間で付与された権限は、それ自体の名前空間と、場合によってはその下の名前空間にのみ適用されます。
ユーザー名前空間の実践
新しいユーザー名前空間を作成するには、unshare -Uを使用するだけです。 コマンド:
[container-user@localhost ~]$ PS1='\u@app-user$ ' unshare -U
nobody@app-user$ 上記のコマンドには、 PS1が含まれています シェルを変更するだけの変数。これにより、シェルがアクティブな名前空間を簡単に判別できます。興味深いことに、ユーザーは誰もいないことに気付くでしょう。 :
nobody@app-user$ whoami
nobody
nobody@app-user$ id
uid=65534(nobody) gid=65534(nobody) groups=65534(nobody) これは、デフォルトでは、ユーザーIDマッピングが行われていないためです。マッピングが定義されていない場合、名前空間は単にシステムのルールを使用して、未定義のユーザーを処理する方法を決定します。
ただし、次のような名前空間を作成する場合:
PS1='\u@app-user$ ' unshare -Ur マッピングは自動的に作成されます:
root@app-user$ cat /proc/$$/uid_map
0 1000 1 このファイルは次のことを表しています:
ID-inside-ns ID-outside-ns range 範囲 値は、マップするユーザーの数を表します。たとえば、これが 0 1000 4の場合 、マッピングは次のようになります
0 1000
1 1001
2 1002
3 1003 等々。ほとんどの場合、あなたはルートだけを本当に気にします ユーザーマッピングですが、必要に応じてオプションを使用できます。 java-userを作成するとどうなりますか 名前空間?
root@app-user$ PS1='\u@java-user$ ' unshare -Ur
root@java-user$ 予想どおり、シェルプロンプトが変更され、あなたはrootユーザーですが、UIDマッピングはどのようになりますか?
root@java-user$ cat /proc/$$/uid_map
0 0 1 これで、 0になりました。 0へ マッピング。これは、新しい名前空間をインスタンス化するユーザーがIDマッピングプロセスに使用されるためです。あなたはルートだったので 以前の名前空間では、新しい名前空間には rootのマッピングがあります ルートへ 。ただし、ルート以降 app-user 名前空間にルートがありません システムでは、新しい名前空間 rootも同様です ユーザー。
単にuid_mapをチェックする以外に 、2つのプロセスが同じ名前空間にあるかどうかを、名前空間の外部から確認することもできます。もちろん、最初にプロセスのPIDを見つける必要がありますが、それが手元にあれば、次のコマンドを実行できます。
readlink /proc/$PID/ns/user これを簡単にするために、次のコマンドを実行しました:
[container-user@localhost ~]$ PS1='\u@app-user$ ' unshare -Ur
root@app-user$ sleep 100000
別の端末で、PIDを掘り起こし、readlinkを使用しました そのPIDと現在のシェルに対するコマンド:
[root@localhost ~]# readlink /proc/1307/ns/user
user:[4026532275]
[root@localhost ~]# readlink /proc/$$/ns/user
user:[4026531837] ご覧のとおり、ユーザーリンクは異なります。それらが同じ名前空間で動作している場合、次のようになります。
[root@localhost ~]# readlink /proc/1424/ns/user
user:[4026532275]
[root@localhost ~]# readlink /proc/1307/ns/user
user:[4026532275] ユーザー名前空間の最大の利点は、root権限なしでコンテナーを実行できることです。さらに、UIDマッピングの設定方法によっては、特定のユーザー名前空間内にスーパーユーザーが存在することを完全に回避できます。これは、このタイプの名前空間内で特権プロセスを実行できないことを意味します。
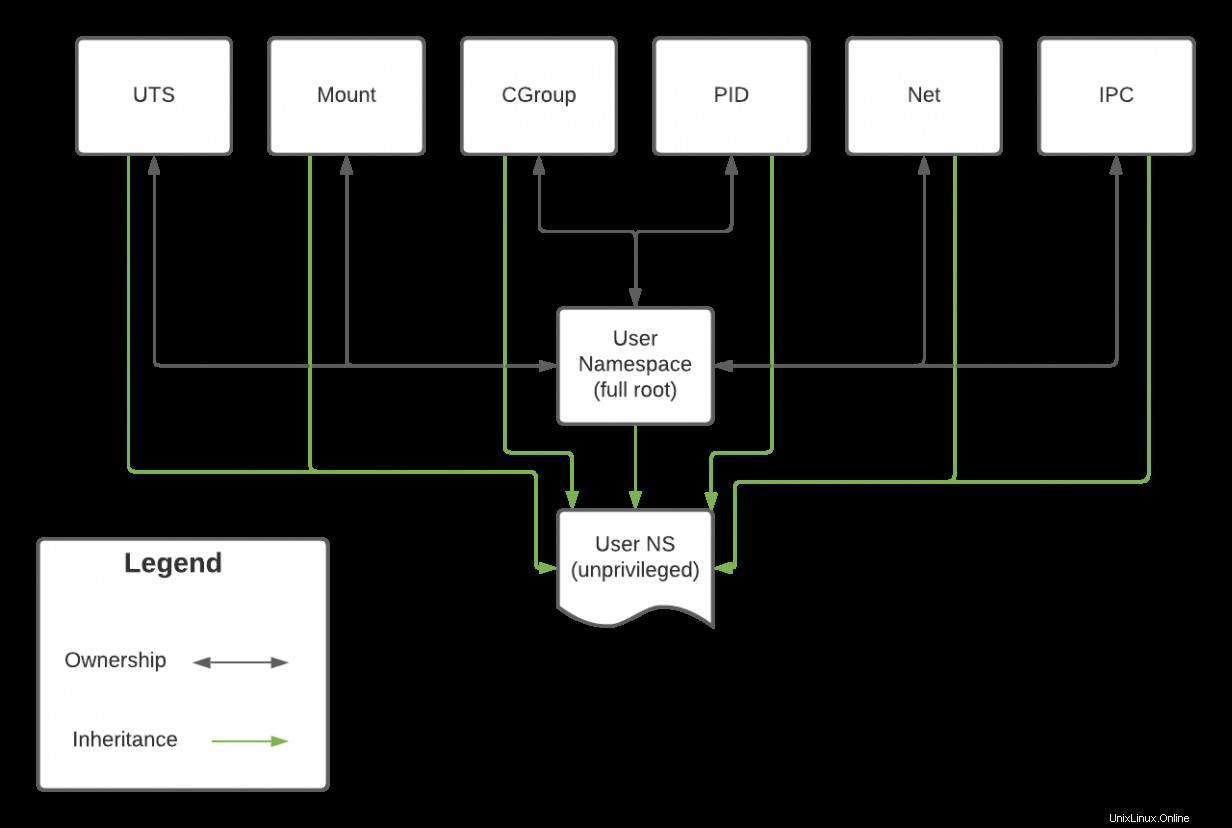
注 :ユーザー 名前空間はすべての名前空間を管理します。これは、名前空間の機能がその親のユーザーの機能に直接関連していることを意味します 名前空間。
元の完全なルート 次の図のシステムでは、ユーザー名前空間がすべての名前空間を所有しています。この関係は双方向になる可能性があります。プロセスがネットで実行されている場合 名前空間はルートとして実行されます 、ルートが所有する他のすべてのプロセスに影響を与える可能性があります ユーザー名前空間。ただし、非特権ユーザー名前空間を作成すると、新しいユーザー名前空間が他の名前空間のリソースにアクセスできるようになりますが、それらを所有していないため、リソースを変更できない場合があります。したがって、非特権名前空間のプロセスはpingできます。 IP(ネットに依存します 名前空間)、ホストのネットワーク構成を変更しない場合があります。
Linuxコンテナーとして考えているもの以外の多くのものは、名前空間を利用します。 Linuxパッケージ形式のFlatpakは、アプリケーションサンドボックスを提供するために、ユーザー名前空間とその他のテクノロジーを使用します。 Flatpaksは、アプリケーションのすべてのライブラリを同じパッケージ配布ファイルにバンドルします。これにより、Linuxマシンは、正しいバージョンのglibcを使用しているかどうかを心配することなく、最新のアプリケーションを受信できます。 たとえば、インストールされます。これらを独自のユーザー名前空間に含めることができるということは、(理論的には)flatpak内の不正なプロセスが、名前空間外のファイルやプロセスを変更(またはアクセスさえ)できないことを意味します。
[コンテナを使い始めますか?この無料コースをチェックしてください。コンテナ化されたアプリケーションのデプロイ:技術的な概要。 ]
まとめ
ユーザーの名前空間を単独で使用しても、Flatpakなどが処理しようとしている問題は解決されません。ユーザー名前空間は、他の名前空間のセキュリティストーリーと機能に不可欠ですが、それ自体では多くを提供しません。新しい分離された名前空間を作成するときは、考慮すべきことがたくさんあります。次の記事では、マウントの使用について見ていきます。 chrootを作成するためのユーザー名前空間と組み合わせた名前空間 -名前空間のある環境のようです。
理解を深めるのに役立ついくつかの課題を探している場合は、さまざまなユーザーを新しい名前空間にマッピングしてみてください。範囲全体を名前空間にマップするとどうなりますか?特権のない名前空間でapacheユーザーになることは可能ですか?悪いuid_mapを書くことのセキュリティへの影響は何ですか ファイル? (ヒント :2つのシェルを開く必要があります。 1つは新しい名前空間を作成して内部に配置し、もう1つはuid_mapを作成するためのものです。 およびgid_map ファイル。これに苦労している場合は、Twitter@linuxovensに連絡してください。