クラスターでの単純なフェイルオーバーの管理にKeepalivedを使用することに関する私の最初の記事を読んだ場合、そのVRRPを思い出すでしょう。 どのサーバーがアクティブマスターになるかを決定するときに、優先度の概念を使用します。優先度が最も高いサーバーが「勝ち」、マスターとして機能し、VIPを保持してリクエストを処理します。 Keepalived システムの状態に基づいて優先度を調整するためのいくつかの便利な方法を提供します。この記事では、Keepalivedとともに、これらのメカニズムのいくつかについて説明します。 サーバーの状態が変化したときにスクリプトを実行するの機能。
これらの例では、server1の構成のみを示します。この時点で、シリーズ全体を読んでいる場合は、server2で必要な構成に慣れていると思います。そうでない場合は、続行する前に、このシリーズの最初と2番目の記事を確認してください。
- クラスター内の単純なフェイルオーバーを管理するためのKeepalivedの使用
- キープアライブを使用したLinuxクラスターのセットアップ:基本構成
VRT Network Equipment Extension、CCBY-SA3.0を介して利用できる図のネットワーク記号。
Keepalived アクティブなマスターが完全に停止した場合やその他の理由で到達不能になった場合など、アドバタイズメントが受信されない場合にフェイルオーバーをトリガーするという優れた機能を果たします。ただし、よりきめ細かいトリガーメカニズムが必要であることがよくあります。たとえば、アプリケーションが独自のヘルスチェックを実行して、クライアントの要求を処理するアプリの機能を判断する場合があります。異常なアプリサーバーが稼働していてVRRPを送信しているという理由だけで、異常なアプリサーバーがアクティブなマスターのままになることは望ましくありません。 広告。
注:Keepalivedのバージョンが見つかりました 標準パッケージリポジトリから入手できるバグには、以下の例の一部が正しく機能しない原因が含まれていました。問題が発生した場合は、Keepalivedをインストールすることをお勧めします 前の記事で説明したように、ソースから。
追跡プロセス
最も一般的なKeepalivedの1つ セットアップには、サーバー上のプロセスを追跡して、ホストの状態を判断することが含まれます。たとえば、高可用性Webサーバーのペアをセットアップし、Apacheがそれらの1つで実行を停止した場合にフェイルオーバーをトリガーすることができます。
Keepalived track_processを介してこれを簡単にします 構成ディレクティブ。以下の例では、Keepalivedを設定しました httpdを見る 重み10で処理します。httpdである限り が実行されている場合、アドバタイズされた優先度は254(244 + 10 =254)になります。 httpdの場合 実行を停止すると、優先度は244に下がり、フェイルオーバーがトリガーされます(server2に同様の構成が存在することを前提としています)。
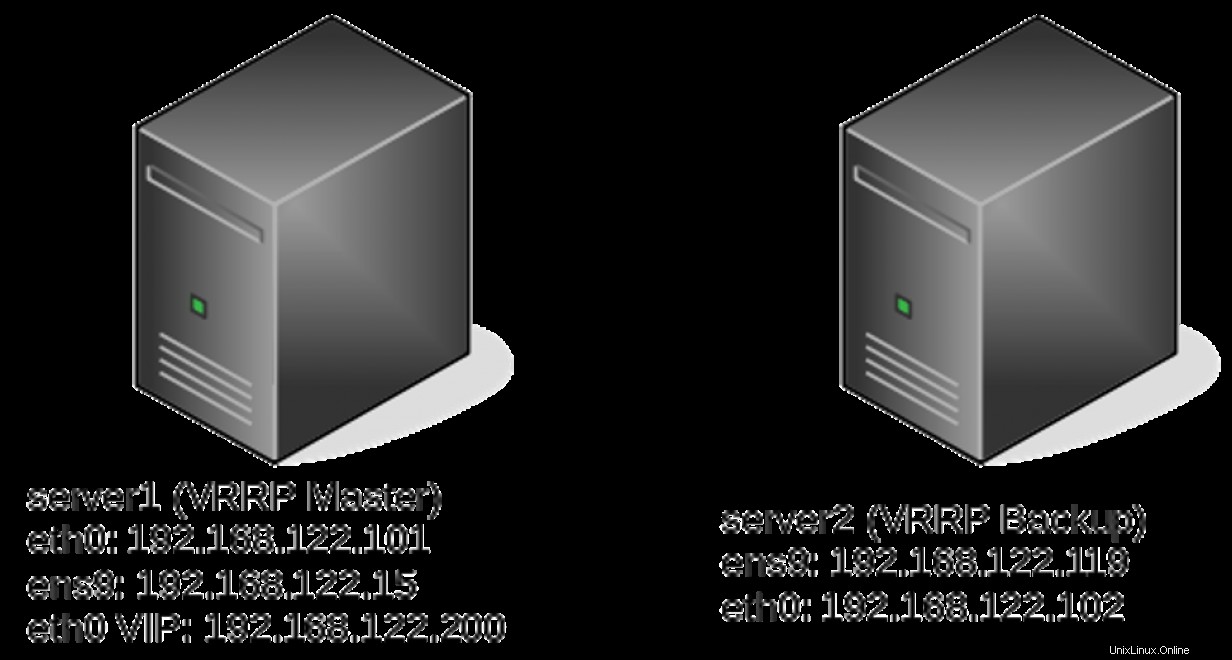
server1# cat keepalived.conf
vrrp_track_process track_apache {
process httpd
weight 10
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_process {
track_apache
}
} この構成が適切に行われている場合(およびApacheがインストールされ、両方のサーバーで実行されている場合)、Apacheを停止し、VIPがserver1からserver2に移動するのを監視することでフェイルオーバーシナリオをテストできます。
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
server1# systemctl stop httpd
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 追跡ファイル
Keepalived また、ファイルの内容に基づいて優先順位を決定する機能もあります。これは、このファイルに値を書き込むことができるアプリケーションを実行している場合に役立ちます。たとえば、定期的にヘルスチェックを実行し、アプリケーションの全体的なヘルスに基づいて値をファイルに書き込むバックグラウンドプロセスがアプリにある場合があります。
Keepalived マニュアルページでは、ファイルの追跡はファイルに設定された重みに基づいていると説明されています:
「値はファイルからテキスト内の数値として読み取られます。 track_fileに対して構成された重みが0の場合、ファイル内のゼロ以外の値は失敗ステータスとして扱われ、ゼロ値はOKステータスとして扱われます。それ以外の場合、値はで構成された重みで乗算されます。 track_fileステートメント。結果が-253未満の場合、スクリプトを監視しているVRRPインスタンスまたは同期グループは障害状態に移行します(ファイルから負の値を読み取ることができるように、重みを254にすることができます)。」
この例では、物事を単純にし、トラックファイルに重み1を使用します。この構成は、/var/run/my_app/vrrp_track_fileにあるファイルの数値を取得します 1を掛けます。
server1# cat keepalived.conf
vrrp_track_file track_app_file {
file /var/run/my_app/vrrp_track_file
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_file {
track_app_file weight 1
}
}
これで、開始値を使用してファイルを作成し、Keepalivedを再起動できます。 。優先度はtcpdumpで確認できます このシリーズの2番目の記事で説明したように、出力。
server1# mkdir /var/run/my_app
server1# echo 5 > /var/run/my_app/vrrp_track_file
server1# systemctl restart keepalived
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:19:32.191562 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 249, authtype simple, intvl 1s, length 20 アドバタイズされた優先度は249であることがわかります。これは、ファイル(5)の値に重み(1)を掛けて、基本優先度(244)に加算した値です。同様に、優先度を6に調整すると、優先度が高くなります。
server1# echo 6 > /var/run/my_app/vrrp_track_file
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:20:43.214940 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 250, authtype simple, intvl 1s, length 20 トラックインターフェース
複数のインターフェースを備えたサーバーの場合、Keepalivedの優先度を調整すると便利な場合があります インターフェイスのステータスに基づくインスタンス。たとえば、フロントエンドVIPと内部ネットワークへのバックエンド接続を備えたロードバランサーは、Keepalivedをトリガーしたい場合があります。 バックエンドネットワークへの接続がダウンした場合のフェイルオーバー。これは、track_interface構成で実現できます:
server1# cat keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_interface {
ens9 weight 5
}
} 上記の設定では、インターフェイスens9のステータスに5の重みが割り当てられています。これにより、ens9が起動している限り、server1は優先度249(244 + 5 =249)を想定します。 ens9がダウンすると、優先度は244に低下します(server2が同じように構成されていると仮定すると、フェイルオーバーがトリガーされます)。マルチインターフェースサーバーでこれをテストするには、インターフェースをオフにして、VIPがホスト間を移動するのを監視します。
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
ens9 UP 192.168.122.15/24 fe80::7444:5ec4:8015:722f/64
server1# ip link set ens9 down
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
ens9 DOWN
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens9 UP 192.168.122.119/24 fe80::fc9f:8999:b93e:d491/64
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 追跡スクリプト
Keepalivedを見てきました ヘルスとその後のVRRPを判断するための便利な組み込みチェックメソッドを多数提供します ホストの優先度。ただし、より複雑な環境では、ニーズを満たすためにヘルスチェックスクリプトなどのカスタムツールを使用する必要がある場合があります。ありがたいことに、Keepalived また、ホストの状態を判断するために任意のスクリプトを実行する機能もあります。スクリプトの重みは調整できますが、この例では簡単に説明します。0を返すスクリプトは成功を示し、それ以外を返すスクリプトはKeepalivedを示します。 インスタンスは障害状態に入る必要があります。
このスクリプトは、みんなのお気に入りの8.8.8.8への簡単なpingです。 以下に示すように、GoogleDNSサーバー。ご使用の環境では、より複雑なスクリプトを使用して、必要なヘルスチェックを実行する可能性があります。
server1# cat /usr/local/bin/keepalived_check.sh
#!/bin/bash
/usr/bin/ping -c 1 -W 1 8.8.8.8 > /dev/null 2>&1
pingに1秒のタイムアウトを使用したことに気付くでしょう。 (-W 1)。 Keepalivedを作成する場合 スクリプトを確認してください。軽量で高速に保つことをお勧めします。スクリプトが遅いため、壊れたサーバーが長期間マスターのままになることは望ましくありません。
Keepalived チェックスクリプトの構成を以下に示します。
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
}
これは、これまで使用してきた構成とよく似ていますが、vrrp_script ブロックにはいくつかの固有のディレクティブがあります:
interval:スクリプトを実行する頻度(1秒)。timeout:スクリプトが戻るまでの待機時間(5秒)。rise:ホストが「正常」であると見なされるために、スクリプトが正常に戻る必要がある回数。この例では、スクリプトは3回正常に戻る必要があります。これは、単一の失敗(または成功)がKeepalivedを引き起こす「フラッピング」状態を防ぐのに役立ちます すばやく前後に反転する状態。fall:ホストが「異常」と見なされるために、スクリプトが失敗した(またはタイムアウトした)回数。これは、riseディレクティブの逆として機能します。
スクリプトを強制的に失敗させることで、この構成をテストできます。以下の例では、iptablesを追加しました 8.8.8.8との通信を防ぐルール 。これにより、ヘルスチェックが失敗し、VIPが数秒後に消えました。その後、ルールを削除して、VIPが再表示されるのを見ることができます。
server1# iptables -I OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
Keepalivedのスクリプトに関する簡単なヒント :root以外の別のユーザーとして実行できます。これらの例ではそのことを示していませんが、マニュアルページを見て、チェックスクリプトによるセキュリティへの悪影響を回避するために、可能な限り最小特権のユーザーを使用していることを確認してください。
スクリプトに通知
Keepalivedをトリガーする方法について話し合ってきました 外部条件に基づく応答。ただし、Keepalivedのときにアクションをトリガーすることもできます。 ある状態から別の状態に遷移します。たとえば、Keepalivedのときにサービスを停止したい場合があります バックアップ状態になります。または、管理者への電子メールを開始することもできます。 Keepalived 通知スクリプトを使用してこれを行うことができます。
Keepalived 特定の状態でスクリプトを呼び出すためのいくつかの通知ディレクティブを提供します(notify_master 、notify_backup など)、ただし、裸のnotifyに焦点を当てます 最も柔軟であるため、ディレクティブ。 notifyのスクリプトが ディレクティブが呼び出されると、4つの追加の引数を受け取ります(スクリプト自体に渡される引数の後に)。
順番にリストされているものは次のとおりです。
- グループまたはインスタンス:通知が
VRRPによってトリガーされるかどうかの表示 グループ(このシリーズでは説明しません)または特定のVRRPインスタンス。 - グループまたはインスタンスの名前
- グループまたはインスタンスが移行中であることを表明します
- 優先順位
例を見ると、これがより明確になります。スクリプトとKeepalived 構成は次のようになります:
server1# cat /usr/local/bin/keepalived_notify.sh
#!/bin/bash
echo "$1 $2 has transitioned to the $3 state with a priority of $4" > /var/run/keepalived_status
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
notify "/usr/local/bin/keepalived_notify.sh"
}
上記の構成では、/usr/local/bin/keepalived_notify.shが呼び出されます。 Keepalivedのたびにスクリプトを作成します 状態遷移が発生します。同じチェックスクリプトが用意されているため、初期状態を簡単に検査してから、遷移をトリガーできます。
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
server1# iptables -A OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the FAULT state with a priority of 244
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
コマンドライン引数は、このセクションの冒頭で説明したものに対応していることがわかります。明らかにこれは単純な例ですが、通知スクリプトは、ルーティングルールの調整や他のスクリプトのトリガーなど、多くの複雑なアクションを実行できます。これらは、Keepalivedに基づいて外部アクションを実行するための便利な方法です。 状態が変化します。
まとめ
この記事は、基本的なKeepalivedを締めくくりました いくつかの高度な概念を持つシリーズ。 Keepalivedをトリガーする方法を学びました プロセスステータス、インターフェイスの変更、さらには外部スクリプトの結果など、外部イベントに基づく優先度と状態の変更。また、Keepalivedに応答して通知スクリプトをトリガーする方法も学習しました。 状態が変化します。これらのアプローチの2つ以上を組み合わせて、複数の外部刺激に応答する可用性の高いLinuxサーバーのペアを構築し、トラフィックが常にクライアント要求を処理できる正常なIPアドレスに到達するようにすることができます。
[システム管理についてもっと知りたいですか?無料のオンラインコースを受講する:Red HatEnterpriseLinuxの技術概要。 ]