ファイル(または一連のファイル)があり、これらのファイル内の特定の文字列または構成設定を検索するとします。各ファイルを個別に開いて特定の文字列を見つけようとするのは面倒で、おそらく適切なアプローチではありません。では、何を使用できるでしょうか?
*nixベースのシステムでテキストを検索および操作するために使用できるツールはたくさんあります。この記事では、grepについて説明します。 ファイル内にあるかストリームからのものかを問わず、パターンを検索するコマンド(ファイルまたはパイプからの入力コンピング、または| )。今後の記事では、sedの使用方法についても説明します。 (ストリームエディタ)ストリームを操作します。
プログラムまたはユーティリティの動作を理解する最良の方法は、そのマニュアルページを参照することです。多くの(すべてではないにしても)Unixツールは、インストール中にマニュアルページを提供します。 Red Hat Enterprise Linuxベースのシステムでは、以下を実行してgrepを一覧表示できます。 のドキュメントファイル:
$ rpm -qd grep
/usr/share/doc/grep/AUTHORS
/usr/share/doc/grep/NEWS
/usr/share/doc/grep/README
/usr/share/doc/grep/THANKS
/usr/share/doc/grep/TODO
/usr/share/info/grep.info.gz
/usr/share/man/man1/egrep.1.gz
/usr/share/man/man1/fgrep.1.gz
マニュアルページを自由に使用できるので、grepを使用できるようになりました。 そしてそのオプションを探ります。
grep 基本
記事のこの部分では、wordsを使用します 次の場所にあるファイル:
$ ls -l /usr/share/dict/words
lrwxrwxrwx. 1 root root 11 Feb 3 2019 /usr/share/dict/words -> linux.words
このファイルには479,826語が含まれており、wordsによって提供されます。 パッケージ。私のFedoraシステムでは、そのパッケージはwords-3.0-33.fc30.noarchです。 。 wordsの内容をリストするとき ファイルの場合、次の出力が表示されます:
$ cat /usr/share/dict/words
1080
10-point
10th
11-point
[……]
[……]
zyzzyva
zyzzyvas
ZZ
Zz
zZt
ZZZ
わかりました。words ファイルには479,826行が含まれていましたが、どうすればそれを知ることができますか?覚えておいてください、私たちは以前にマニュアルページについて話しました。 grepかどうか見てみましょう 特定のファイルの行をカウントするオプションを提供します。
皮肉なことに、grepを使用します 次のようにオプションをgrepします:

したがって、明らかに-cが必要です。 、または長いオプション--count 、特定のファイルの行数をカウントします。 /usr/share/dict/wordsの行を数える 収量:
$ grep -c '.' /usr/share/dict/words
479826
'.' 少なくとも1つの文字、スペース、空白、タブなどを含むすべての行をカウントすることを意味します。
grep 正規表現
grep 正規表現(regexes)を使用すると、コマンドがより強力になります。したがって、grepに焦点を当てながら コマンド自体については、基本的な正規表現の構文についても触れます。
Zで始まる単語にのみ関心があると仮定しましょう。 。この状況では、正規表現が役立ちます。カラットを使用します(^ )文字列の先頭を示す特定の文字で始まるパターンを検索するには:
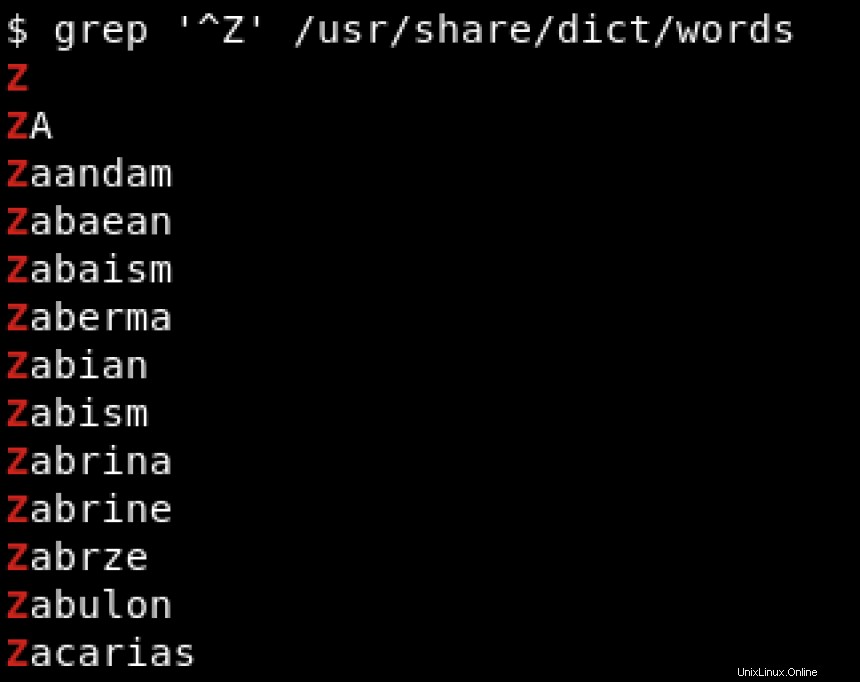
特定の文字で終わるパターンを検索するには、ドル記号($)を使用します )文字列の終わりを示します。 hatで終わる文字列を検索する以下の例を参照してください。 :
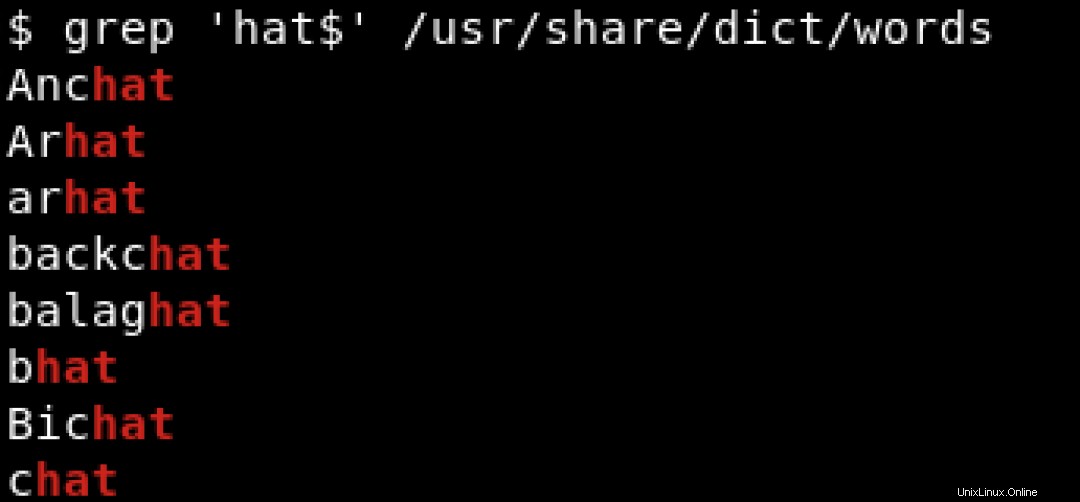
hatを含むすべての行を印刷するには 行の先頭でも末尾でも、その位置に関係なく、次のようなものを使用します。
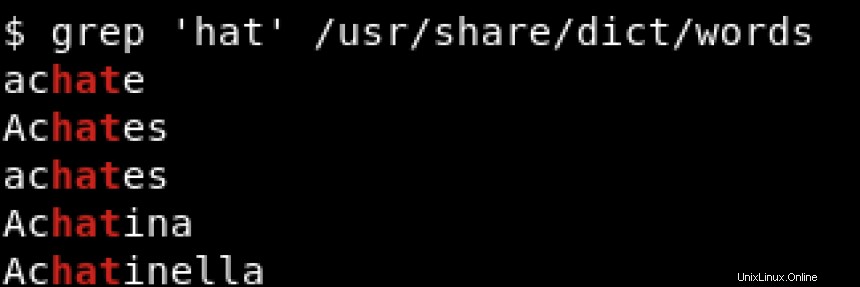
^ および$ メタ文字と呼ばれ、円記号(\)でエスケープする必要があります )これらの文字を文字通り一致させたい場合。メタ文字について詳しく知りたい場合は、https://www.regular-expressions.info/characters.htmlを参照してください。
例:コメントを削除する
これで、grepの表面をスクラッチしました 、実際のシナリオに取り組みましょう。 * nixの多くの構成ファイルには、構成ファイル内のさまざまな設定を説明するコメントが含まれています。 /etc/fstab 、たとえば、ファイルには次のものがあります:
$ cat /etc/fstab
#
# /etc/fstab
# Created by anaconda on Thu Oct 27 05:06:06 2016
#
# Accessible filesystems, by reference, are maintained under '/dev/disk'
# See man pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info
#
/dev/mapper/VGCRYPTO-ROOT / ext4 defaults,x-systemd.device-timeout=0 1 1
UUID=e9de0f73-ddddd-4d45-a9ba-1ffffa /boot ext4 defaults 1 2
LABEL=SSD_SWAP swap swap defaults 0 0
#/dev/mapper/VGCRYPTO-SWAP swap swap defaults,x-systemd.device-timeout=0 0 0
コメントはハッシュ(#)でマークされています )、印刷時に無視したい。 1つのオプションはcatです コマンド:
$ cat /etc/fstab | grep -v '^#'
ただし、catは必要ありません ここで(猫の無用な使用を避けてください)。 grep コマンドはファイルを完全に読み取ることができるため、代わりに次のようなものを使用して、コメントを含む行を無視できます。
$ grep -v '^#' /etc/fstab
代わりに、出力(コメントなし)を別のファイルに送信する場合は、次を使用します。
$ grep -v '^#' /etc/fstab > ~/fstab_without_comment
grep 画面上の出力をフォーマットできますが、このコマンドはその場でファイルを変更できません。これを行うには、edのようなファイルエディタが必要です 。次の記事では、sedを使用します ここでgrepを使用して行ったのと同じことを実現するため 。
例:コメントと空の行を削除する
まだgrepを使用している間 、/etc/sudoersを調べてみましょう ファイル。このファイルには多くのコメントが含まれていますが、コメントのない行にのみ関心があり、空の行も削除したいと考えています。
それでは、まず、コメントを含む行を削除しましょう。次の出力が生成されます:
# grep -v '^#' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
ここで、空白の(空の)行を削除します。それは簡単です。別のgrepを実行するだけです。 コマンド:
# grep -v '^#' /etc/sudoers | grep -v '^$'
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
もっと上手くできますか? grepを実行できますか grepをフォークせずに、よりリソースに優しいコマンド 二度?確かに次のことができます:
# grep -Ev '^#|^$' /etc/sudoers
Defaults !visiblepw
Defaults env_reset
Defaults env_keep = "COLORS DISPLAY HOSTNAME HISTSIZE KDEDIR LS_COLORS"
Defaults env_keep += "MAIL PS1 PS2 QTDIR USERNAME LANG LC_ADDRESS LC_CTYPE"
Defaults env_keep += "LC_COLLATE LC_IDENTIFICATION LC_MEASUREMENT LC_MESSAGES"
Defaults env_keep += "LC_MONETARY LC_NAME LC_NUMERIC LC_PAPER LC_TELEPHONE"
Defaults env_keep += "LC_TIME LC_ALL LANGUAGE LINGUAS _XKB_CHARSET XAUTHORITY"
Defaults secure_path = /usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin
root ALL=(ALL) ALL
%wheel ALL=(ALL) ALL
valentin.local ALL=NOPASSWD: /usr/bin/updatedb
ここでは、別のgrepを紹介しました オプション、-E (または--extended-regexp )<PATTERN> は拡張正規表現です。
例:/etc/passwdのみを印刷する ユーザー
grepであることは明らかです 正規表現とともに使用すると強力です。この記事では、grepのほんの一部を取り上げています。 本当に可能です。 grepの機能をデモンストレーションする 正規表現を使用して、/etc/passwdを解析します ユーザー名のみをファイルして印刷します。
/etc/passwdの形式 ファイルは次のとおりです:
$ head /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
上記のフィールドの意味は次のとおりです。
<name>:<password>:<UID>:<GID>:<GECOS>:<directory>:<shell>
man 5 passwdを参照してください /etc/passwdの詳細については ファイル。ユーザー名のみを印刷するには、次のようなものを使用できます。
$ grep -Eo '^[a-zA-Z_-]+' /etc/passwd
root
bin
daemon
adm
lp
sync
shutdown
halt
mail
operator
上記のgrep コマンド、別のオプションを導入しました:-o (または--only-matching )<PATTERN>に一致する行の一部のみを表示します 。次に、-Eoを組み合わせました 目的の結果を得るには。
ここで、上記のコマンドを分割して、実際に何が起こっているのかをよりよく理解できるようにします。左から右へ:
-
^行の先頭で一致します。 -
[a-zA-Z_-]は文字クラスと呼ばれ、含まれるリストに一致する単一の文字と一致します。 -
+は、1回から無制限の回数に一致する数量詞です。
上記の正規表現は、一致しない文字に到達するまで繰り返されます。ファイルの最初の行は次のとおりです。
root:x:0:0:root:/root:/bin/bash
次のように処理されます:
- 最初の文字は
rです 、したがって、[a-z]と一致します 。 -
+次のキャラクターに移動します。 - 2番目の文字は
oです これは[a-z]と一致します 。 -
+次のキャラクターに移動します。
このシーケンスは、コロンに当たるまで繰り返されます(: )。文字クラス[a-zA-Z_-] :と一致しません シンボルなので、grep 次の行に移動します。
passwdのユーザー名以降 ファイルはすべて小文字です。次のように文字クラスを簡略化しても、目的の結果を得ることができます。
$ grep -Eo '^[a-z_-]+' /etc/passwd
例:プロセスを見つける
psを使用する場合 プロセスをgrepするために、私たちはしばしば次のようなものを使用します:
$ ps aux | grep ‘thunderbird’
しかし、ps コマンドはthunderbirdをリストするだけではありません 処理する。 grepも一覧表示されます grepなので、コマンドも実行しました パイプの後にも実行されており、プロセスリストに表示されます:
$ ps aux | grep thunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
val+ 14064 0.0 0.0 57 82 pts/2 S+ 21:12 0:00 grep --color=auto thunderbird
これは、grep -v grepを追加することで処理できます。 grepを除外する 出力から:
$ ps aux | grep thunderbird | grep -v grep
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
grep -v grepを使用している間 新しいgrepをフォークせずに同じ結果を達成するための、より良い方法が存在します。 プロセス:
$ ps aux | grep [t]hunderbird
val+ 2196 0.7 2.1 52 33 tty2 Sl+ 16:47 1:55 /usr/lib64/thunderbird/thunderbird
[t]hunderbird ここでは、リテラルのtと一致します 、および大文字と小文字が区別されます。 grepとは一致しません 、そのため、現在はthunderbirdのみが表示されています。 出力で。
この例は、grepがいかに柔軟であるかを示す単なるデモンストレーションです。 つまり、プロセスツリーのトラブルシューティングには役立ちません。 pgrepのように、この目的に適したより優れたツールがあります 。
grepを使用する ファイルまたは複数のディレクトリでパターンを再帰的に検索する場合。 grepで正規表現がどのように機能するかを理解してください 、正規表現は強力な場合があるためです。
[Red Hat Enterprise Linuxを試してみませんか?今すぐ無料でダウンロードしてください。]