sysadminの作業を十分に長く行っている場合は、恐ろしい「サーバーが遅い」というインシデントが発生しています。長い間、これらのタイプの事件は私に私の胃の穴を与えました。どうやってそんなに主観的なものをトラブルシューティングしますか?日常のユーザーの「遅い」は、他のプロセス(スケジュールされているかどうかに関係なく)が実行され、通常よりも多くのリソースを消費していることが原因である可能性があります。または、サーバーに何か問題がある可能性があります。
私が最初にシステム管理者として働き始めたとき、私はすぐに「これについてもっと情報が必要です」と答えました。ええと、通常、ユーザーは舞台裏で何が実行されているのか、「ただ遅い」以外に何を見ているのかを説明する方法がわからないため、これ以上情報を提供することはできません。最近では、ユーザーに返信する前に、いくつか確認します。
ホストにログインすることでわかることはたくさんあります。まったくログインできますか?ログインが遅いですか、ハングしていますか? ssh コマンドには3つのデバッグレベルがあり、それぞれがシステムにアクセスする前に大量の情報を提供します。デバッグを有効にするには、vを追加するだけです。 -vへ オプション。たとえば、私が独占的に使用しているレベル3のデバッグは、次のようになります。
[~]$ ssh -vvv hostname.domain.com
「ビッグ3」(別名CPU、RAM、およびディスクI / O)
次に、サーバーの速度低下の3つの最大の原因であるCPU、RAM、およびディスクI/Oを見てみましょう。 CPU使用率は、ホストの全体的な速度低下を引き起こし、タイムリーにタスクを完了するのを困難にする可能性があります。 CPUを見るときに使用するツールには、topがあります。 およびsar 。
topを使用したCPU使用率の確認
top ユーティリティを使用すると、サーバーで何が起こっているかをリアルタイムで確認できます。デフォルトでは、top 開始すると、すべてのCPUのアクティビティが表示されます:

このビューは、数値の1キーを押すことで変更できます。これにより、各CPUの使用量の値に関する詳細が追加されます。
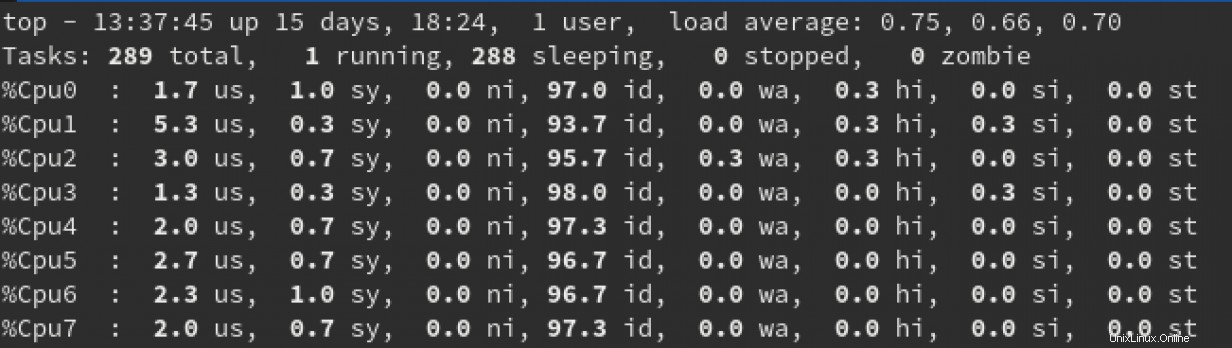
このビューで探すべきいくつかのことは、負荷平均(一番上の行の右側に表示されます)、および各CPUの次の値です:
us:このパーセンテージは、ユーザープロセスによって消費されたCPUの量を表します。-
sy:このパーセンテージは、システムプロセスによって消費されるCPUの量を表します。 -
id:このパーセンテージは、各CPUがどれだけアイドル状態であるかを表します。
これらの3つの値はそれぞれ、CPUがユーザープロセスとシステムプロセスのどちらにバインドされているかをリアルタイムで把握できます。
負荷平均を真に説明するには、それ自体で記事が必要になります。この記事の目的のために、私は一般的に話します。左から右への3つの負荷平均値は、1分、5分、および15分の平均を表します。繰り返しますが、非常に 一般に、1分間の平均が使用している物理CPUの数を上回っている場合は、システムがCPUにバインドされている可能性があります。
注: 負荷平均の詳細と、それがばかげた数値だと考える人がいる理由については、ブレンダングレッグの詳細な調査をご覧ください。
sarですべての「Big3」をチェック
過去のCPUパフォーマンスデータについては、sarに依存しています sysstatによって提供されるコマンド パッケージ。 Linuxのほとんどのサーバーバージョンでは、sysstat デフォルトでインストールされますが、インストールされていない場合は、ディストリビューションのパッケージマネージャーで追加できます。 sar ユーティリティは、/etc/cron.d/sysstatにあるcronジョブを介して10分ごとにシステムデータを収集します (CentOS 7.6)。 sarを使用してすべての「Big3」を確認する方法は次のとおりです 。
注: sarをインストールしたばかりの場合 この記事を続けるために、最初にデータを記録する時間をコマンドに与えてください。
コマンドsar -u 深夜から、システム上のすべてのCPUに関する情報を提供します:

topと同様 、ここで確認する主なことは%userです。 、%system 、%iowait 、および%idle 。この情報から、サーバーで問題が発生していた期間がわかります。
全体として、sar コマンドは多くの情報を提供できます。この記事では、サーバーで何が起こっているかを簡単に確認する方法について説明しているので、man sarを確認してください。 この情報をさらに細かく分類します。
RAMのパフォーマンスを確認するには、sar -rを使用します 、その日のメモリ使用量を示します:

RAM使用量で探すべき主なものは、%memusedです。 および%commit 。 %commitについて簡単に説明します。 フィールド:Linuxカーネルは定期的にRAMをオーバーコミットするため、このフィールドは100%を超えて表示される可能性があります。 %commitの場合 が常に100%を超えている場合、この結果は、システムがより多くのRAMを必要としていることを示している可能性があります。
ディスクI/Oのパフォーマンスについては、sar -dを使用します 、デバイス名だけを使用してディスクI/O出力を提供します。デバイスの名前を取得するには、sar -dPを使用します :

この出力については、%utilを見てください。 および%await システム上のディスクI/Oの全体像を把握できます。 %util フィールドはかなり自明です:それはそのデバイスの使用率です。 await フィールドには、I/Oがスケジューラーで費やす時間が含まれます。 Awaitはミリ秒単位で測定されますが、私の環境では、50ミリ秒を超えると問題が発生し始めることがわかりました。そのしきい値は、環境によって異なる場合があります。
これらのコマンドのいずれかで問題が発生した場合は、sar {-u, -r, -d, -dP} -f /var/log/sa/sa<XX> (ここでXX 探したい月の日です。
この時点で、私は通常、サーバーで現在何が起こっているのか、そして過去48時間ほど何が起こっているのかをよく理解しています。より多くの情報に基づいてユーザーに返信します。例:「過去24時間にホストの速度低下の兆候は見られません。新しいパテプロファイルを使用して、sshを試してください。 で、引き続き問題が発生する場合はお知らせください。」
別の例:「このホストで現在問題を引き起こしているものは何もありませんが、CPU負荷が高いことに気づきました$time 。それはあなたが問題を見たときですか?その場合は、今すぐ試して、引き続き問題が発生するかどうかをお知らせください。」
あなたはその考えを理解します。最初のログインを確認してから、いくつかのsarを実行して、情報を提供します。 コマンドは、通常、実行に10分もかからず、より多くの質問に頭を悩ませ、より早く解決に到達するために多くのことを行います。