圧縮は、プログラム、サービス、およびユーザーがスペースを節約し、サービスの品質を向上させるために使用する重要なコンピューターサイエンス技術です。たとえば、ゲームプラットフォームを介してゲームをダウンロードする場合、時間とスペースを節約できるように、通常は圧縮バージョンがダウンロードされます。解凍は、ファイルのダウンロード後またはインストールプロセス中に行われます。
しかし、なぜ私はあなたにこれをすべて話しているのですか?さて、今日はLinuxファイル圧縮について説明し、知っておくべきことをすべて紹介します。
圧縮について
Linuxの圧縮について学ぶ前に、まず圧縮についてもっと理解しましょう。
圧縮は、さまざまな数学的計算とアルゴリズムを使用して、特定のディスク上のファイルサイズを縮小する手法です。圧縮の主な目的は、スペースを節約することです。これは、ファイルがハードディスクドライブに保存される方法で可能です。アルゴリズムまたは数学的計算は、パターンを見つけてその部分を圧縮し、詳細をほとんどまたはまったく失うことなくパターンを生成できるようにします。つまり、繰り返されるコンテンツは、圧縮が機能するための道を開きます。
知っておくべき圧縮には2つのタイプがあります。非可逆圧縮と可逆圧縮です。
可逆圧縮
これは情報を失わない圧縮技術であり、実際のデータは圧縮ファイルから取得できます。非可逆圧縮は、元のファイルの品質を損なうことなくファイルサイズを縮小するのに役立ちます。
非可逆圧縮
一方、スペースを節約するためにファイルを圧縮する不可逆圧縮技術ですが、圧縮されたファイルを使用して元のファイルの内容を取得することはできません。この場合、情報は失われます。
これを理解するために、例を見てみましょう。生の画像を取得してから、非可逆および可逆モードを使用して圧縮できます。可逆圧縮では、画像サイズがわずかに小さくなり、画像を解凍すると元の画像を保持できるようになります。ほとんどの場合、可逆圧縮にはPNG形式が使用されます。ただし、非可逆圧縮を使用すると、元の画像に戻すことができない画像出力が得られます。この場合、結果の画像はJPEG/JPG形式です。
圧縮アルゴリズムはその方法が優れており、ユーザーに価値を提供します。新しいアルゴリズムは、圧縮技術が高速で正確な適応手法を使用しています。
Linuxでファイルを圧縮するさまざまな方法
Linuxでの圧縮を理解するには、最初に圧縮方法をテストするためのファイルを作成する必要があります。そのために、次の手順を使用してファイルをランダムに生成できます。
base64 /dev/urandom | head -c 3000000 > mynewfile.txt
新しく作成されたファイルのサイズを知るには、次のコマンドを実行できます。
ls -l --block-size=MB
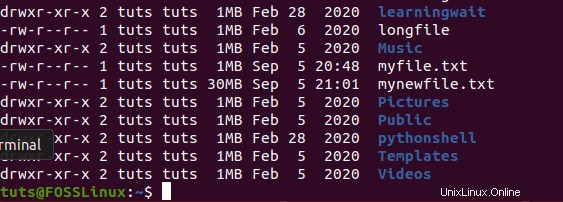
ファイルエクスプローラーを使用してファイルサイズを確認し、そのプロパティでファイルサイズを確認することもできます。
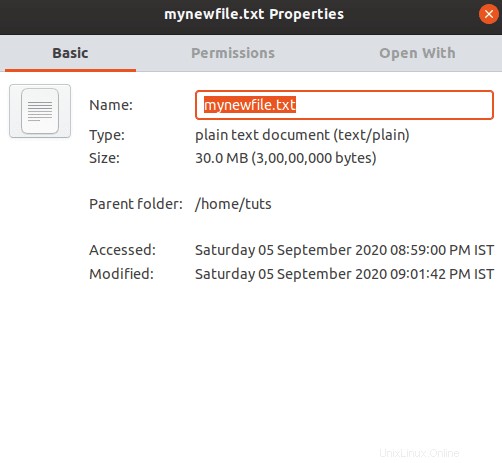
ファイルの複数のコピーを作成して、圧縮技術をテストするために使用できるようにしましょう。

ファイルが保存されているフォルダの合計サイズは150MBです。
Zip圧縮
Linuxに見られる標準的な圧縮技術の1つは、zip圧縮技術です。所有しているファイルに対してzipコマンドを実行するには、次のコマンドを実行する必要があります。
zip <output>.zip <input>
したがって、フォルダ内にある5つのファイルを圧縮するには、次のコマンドを実行する必要があります。
zip testing1.zip *
コマンドの実行には時間がかかり、目の前でコマンドが実行されるのがわかります。
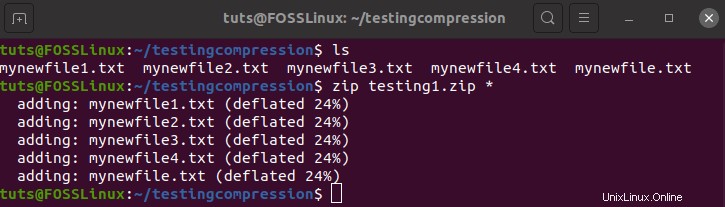
ご覧のとおり、各ファイルは24%削減されました。 24%の節約で、最終的なサイズは114MBになります。それはとても良いことです。追加のソースファイルを使用した場合、結果は異なります。もう1つ気付いたのは、デフレート圧縮技術を使用していることです。
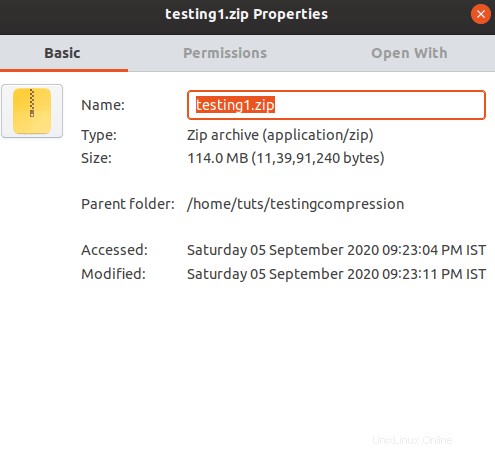
ファイルを解凍するには、次のコマンドを使用する必要があります。
ご覧のとおり、目的地を設定できます。宛先パラメータなしでコマンドを使用するだけで、同じフォルダに解凍することもできます。
Gzip圧縮
zip圧縮を実行したので、GNUZipまたはgzip圧縮の時間です。これは、Linuxでファイルを圧縮するための一般的な方法でもあります。ジャン=ルー・ガイリーとマーク・アドラーが作成します。
また、圧縮率が高いため、zip圧縮方式よりも優れています。 Gzip圧縮を使用するための構文は次のとおりです。
gzip <option> <input>
持っているファイルを圧縮するには、次のコマンドを使用する必要があります。
gzip -v mynewfile1.txt
これにより、ファイル「mynewfile1.txt」が圧縮され、「mynewfile1.txt.gz」という名前が付けられます。

ファイルの最終的なサイズは22.8MBで、これは非常に印象的な圧縮です。
-r recursiveフラグを使用して、フォルダー全体を圧縮することもできます。構文は次のとおりです。
gzip -r <folder_path>
Gzipの圧縮レベルをカスタマイズすることもできます。圧縮レベルの値は1〜9の範囲で設定できます。1は最も高速で最小の圧縮を表し、9は最も低速で最高の圧縮を表します。
gzip -v -9 mynewfile1.txt
gzipファイルを解凍するには、次のコマンドを使用する必要があります。
gzip -d <gzip_file>
Bzip2圧縮
ここで説明する最後の圧縮タイプはBzip2です。これはオープンソースの無料ツールです。 Burrows-Wheelerアルゴリズムを利用しています。
圧縮技術は1996年に最初に導入されたため、かなり古いものです。Bzip2は日常業務で使用できます。高速で、gzipツールと同様に機能します。 Bzip2圧縮技術の構文は次のとおりです。
bzip2 <option> <input>
bzip2を使用してファイルを圧縮してみましょう。

gzipと同様に、圧縮の強さを1から9に設定することもできます。
ファイルを解凍するには、次のコマンドを使用する必要があります。
bzip2 -d <filename>
アーカイブ
ここで学ぶ必要のあるもう1つの重要な用語があります。
アーカイブは、圧縮形式(通常)を使用してデータを安全な場所にバックアップする方法です。 Linuxサーバーには、アーカイブファイルであることを意味するtarファイル拡張子があります。 tar形式は、さまざまなファイルの操作とアドレス指定に関して優れています。メタデータと権限をそのまま保持できるため、主にLinuxシステムのアーカイブ目的で使用されます。
tarコマンドの構文は次のとおりです。
tar <option> <output_file> <input>
抽出するには、次のコマンドを使用する必要があります。
tar -xvf <archieved-file-name>
結論
これで、Linux圧縮ガイドは終わりです。ご覧のとおり、ファイル圧縮を行う方法はたくさんあります。また、アーカイブプロセスには独自の用途があります。では、Linuxファイルの圧縮についてどう思いますか?よく使いますか?以下のコメントでお知らせください。