グラフィカルユーザーインターフェース ワードプロセッサとメモ取りアプリケーションには、ページ数などのドキュメントの詳細に関する情報または詳細インジケータがあります。 、言葉 、および文字 、ワードプロセッサの見出しリスト、一部のマークダウンエディタの目次など、単語やフレーズの出現を見つけるのは、Ctrl + Fを押すのと同じくらい簡単です。 検索したい文字を入力します。
GUI すべてが簡単になりますが、コマンドラインからしか作業できず、テキストファイルに単語、フレーズ、または文字が出現する回数を確認したい場合はどうなりますか?適切なコマンドがあり、それがどのように行われるかを説明しようとしている限り、GUIを使用する場合とほぼ同じくらい簡単です。
example.txtがあるとします。 文を含むファイル:
mauris eu tortorporttitoraccumsanに登場。 Mauris suscipit、ligula sit amet pharetra semper、nibh ante cursus purus、vel sagittis velit mauris vel metus eneanfermentumrisus。
grepコマンドを使用して、"mauris"の回数をカウントできます。 図のようにファイルに表示されます。
$ grep -o -i mauris example.txt | wc -l </ pre>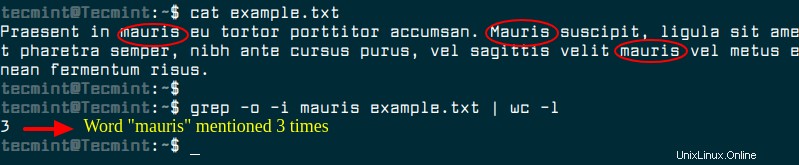
grep -cを使用する 単独では、一致の総数ではなく、一致する単語を含む行の数がカウントされます。-oオプションは、grepに各一致を一意の行に出力してからwc -lを出力するように指示するものです。 行数をカウントするようにwcに指示します。これにより、一致する単語の総数が推定されます。別のアプローチは、trコマンドを使用して入力ファイルの内容を変換し、すべての単語が1行になるようにしてから、
grep -cを使用することです。 その一致カウントをカウントします。$ tr'[:space:]''[\ n *]'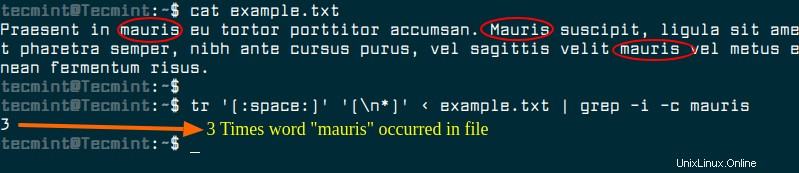
これは、端末から単語の出現を確認する方法ですか?あなたの経験を私たちと共有し、あなたがタスクを達成する別の方法を持っているかどうか私たちに知らせてください。
Linux