このガイドでは、テキストファイル内の一致する文字列またはパターンを検索するために使用されるいくつかの最高のコマンドラインツールのツアーを行います。これらのツールは通常、正規表現と一緒に使用されます– REGEXと短縮されます –これは検索パターンを説明するための一意の文字列です。
面倒なことはせずに、飛び込みましょう。
1。 Grepコマンド
そもそもgrepユーティリティツールが登場します–これはグローバル正規表現印刷の頭字語です。 は、ファイル内の特定の文字列またはパターンを検索するときに便利な強力なコマンドラインツールです。
grep 最新のLinuxディストリビューションがデフォルトで付属しており、さまざまな検索結果を柔軟に返すことができます。 grepを使用すると、次のようなさまざまな機能を実行できます。
- ファイル内の文字列または一致するパターンを検索します。
- Gzip圧縮されたファイルで文字列または一致するパターンを検索します。
- 一致する文字列の数を数えます。
- 文字列またはパターンを含む行番号を印刷します。
- ディレクトリ内の文字列を再帰的に検索します。
- 逆検索を実行します(つまり、検索条件に一致しない文字列の結果を表示します)。
- 文字列を検索するときに大文字と小文字の区別を無視します。
grepを使用するための構文 コマンドは非常に簡単です:
$ grep pattern FILE
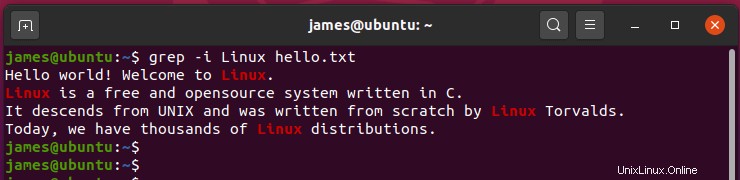
たとえば、文字列「 Linux」を検索するには ‘ファイル内、たとえば hello.txt 大文字と小文字の区別を無視して、次のコマンドを実行します:
$ grep -i Linux hello.txt

grepで使用できるオプションをさらに取得するには 、より高度なgrepコマンドの例を示す記事を読んでください。
2。 sedコマンド
Sed – Stream Editorの略 –は、テキストファイル内のテキストを操作するためのもう1つの便利なコマンドラインツールです。 Sedは、特定のファイル内の文字列を非対話型の方法で検索、フィルタリング、および置換します。
デフォルトでは、 sed コマンドは、出力を STDOUTに出力します (スタンダードアウト )、実行の結果がファイルに保存されるのではなく、端末に出力されることを意味します。
Sedコマンドは次のように呼び出されます:
$ sed -OPTIONS command [ file to be edited ]
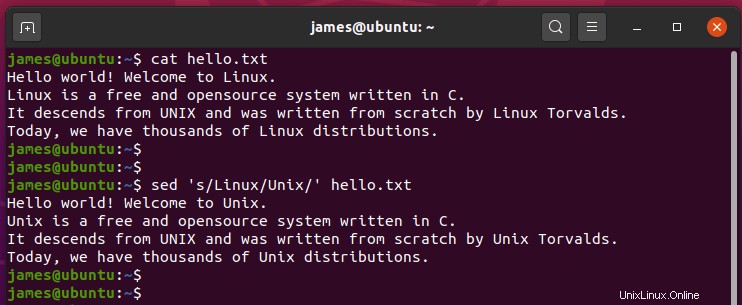
たとえば、「 Unix」のすべてのインスタンスを置き換えるには ‘と‘ Linux ‘、コマンドを呼び出します:
$ sed 's/Unix/Linux' hello.txt
出力を端末に出力する代わりにリダイレクトする場合は、リダイレクト記号( > )を使用します 示されているように。
$ sed 's/Unix/Linux' hello.txt > output.txt
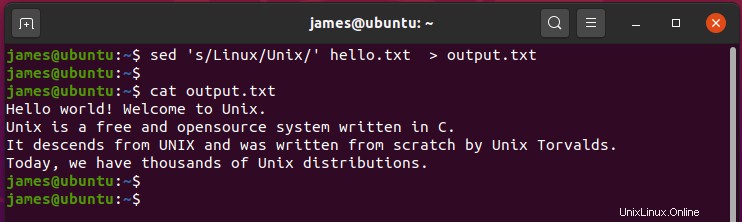
コマンドの出力はoutput.txtに保存されます 画面に印刷する代わりにファイル。
使用できるその他のオプションを確認するには、マニュアルページをもう一度確認してください。
$ man sed
3。 Ackコマンド
確認 Perlで書かれた高速でポータブルなコマンドラインツールです。 確認 grepユーティリティのフレンドリーな代替品と見なされます 結果を視覚的に魅力的な方法で出力します。
確認 コマンドは、ファイルまたはディレクトリで、検索条件に一致する行を検索します。次に、行内の一致する文字列を強調表示します。
確認 ファイル拡張子と、ある程度はファイル内のコンテンツに基づいてファイルを区別する機能があります。
Ackコマンド構文:
$ ack [options] PATTERN [FILE...] $ ack -f [options] [DIRECTORY...]
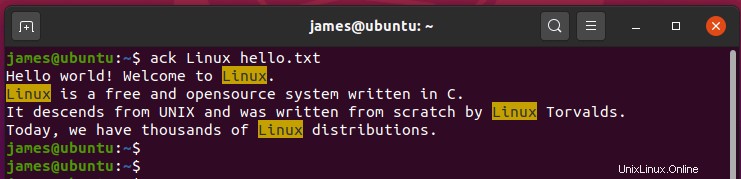
たとえば、検索語 Linuxを確認するには 、実行:
$ ack Linux hello.txt
検索ツールは非常にインテリジェントであり、ユーザーがファイルまたはディレクトリを提供していない場合は、現在のディレクトリとサブディレクトリで検索パターンを検索します。
以下の例では、ファイルまたはディレクトリは提供されていませんが、ackは利用可能なファイルを自動的に検出し、提供された一致パターンを検索しました。
$ ack Linux

ackをインストールするには システムで次のコマンドを実行します:
$ sudo apt install ack-grep [On Debian/Ubuntu] $ sudo dnf install ack-grep [On CentOS/RHEL]
4。 Awkコマンド
Awk は本格的なスクリプト言語であり、テキスト処理およびデータ操作ツールでもあります。検索パターンを含むファイルまたはプログラムを検索します。文字列またはパターンが見つかったら、 awk 一致または行に対してアクションを実行し、結果を STDOUTに出力します 。
AWK プログラム全体が一重引用符で囲まれている間、パターンは中括弧で囲まれています。
最も簡単な例を見てみましょう。次のようにシステムの日付を印刷していると仮定します。
$ date

曜日である最初の値のみを出力したいとします。その場合、出力を awkにパイプします 示されているように:
$ date | awk '{print $1}'
後続の値を表示するには、次のようにコンマを使用して値を区切ります。
$ date | awk '{print $1,$2}'
上記のコマンドは、曜日と月の日付を表示します。

awkで使用できるオプションをさらに取得するには 、awkコマンドシリーズを読んでください。
5。シルバーサーチャー
シルバーサーチャーは、 ackに似たクロスプラットフォームのオープンソースコード検索ツールです。 しかし、スピードに重点を置いています。可能な限り短い時間でファイル内の特定の文字列を簡単に検索できます:
構文:
$ ag OPTIONS search_pattern /path/to/file
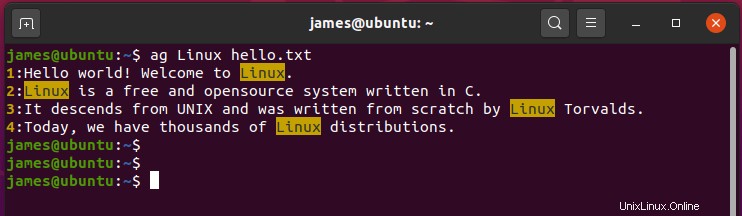
たとえば、文字列「 Linux」を検索するには ‘ファイル内 hello.txt コマンドを呼び出します:
$ ag Linux hello.txt
その他のオプションについては、manページにアクセスしてください:
$ man ag
6。 Ripgrep
最後に、ripgrepコマンドラインツールがあります。 Ripgrep 正規表現パターンを検索するためのクロスプラットフォームユーティリティです。前述のすべての検索ツールよりもはるかに高速で、一致するパターンを探すためにディレクトリを再帰的に検索します。速度とパフォーマンスの点で、 Ripgrepほど目立つツールは他にありません。 。
デフォルトでは、 ripgrep バイナリファイル/隠しファイルとディレクトリをスキップします。また、デフォルトでは、 .gitignore / .ignore / .rgignoreによって無視されるファイルは検索されないことに注意してください。 ファイル。
Ripgrep また、特定のファイルタイプを検索することもできます。たとえば、検索を Javascriptに制限します 実行されるファイル:
$ rg -Tsj
ripgrepを使用するための構文は非常に簡単です:
$ rg [OPTIONS] PATTERN [PATH...]
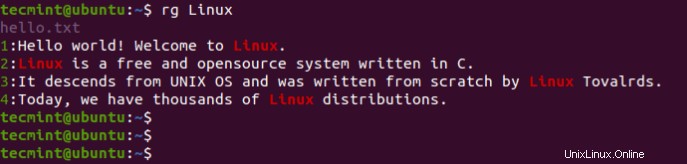
例えば。文字列「Linux」のインスタンスを検索するには 現在のディレクトリ内にあるファイルで、次のコマンドを実行します:
$ rg Linux
ripgrepをインストールするには システムで次のコマンドを実行します:
$ sudo apt install ripgrep [On Debian/Ubuntu] $ sudo pacman -S ripgrep [On Arch Linux] $ sudo zypper install ripgrep [On OpenSuse] $ sudo dnf install ripgrep [On CentOS/RHEL/Fedora]
その他のオプションについては、manページにアクセスしてください:
$ man rg
これらは、Linuxでテキストを検索、フィルタリング、および操作するために最も広く使用されているコマンドラインツールの一部です。他に省略していると思われるツールがある場合は、コメントセクションでお知らせください。