はじめに
ファイルを1行ずつ読み取ると、ファイルの内容を効果的に処理し、各行をリストの要素として出力できます。各行を個別に表示した後、特定のコンテンツを簡単に検索または一致させます。
個々の行のテキストファイルを読み取る方法の1つは、Bashシェルを使用することです。
このチュートリアルでは、Bashでファイルを1行ずつ読み取る方法を学習します。

前提条件
- Linuxを実行しているシステム。
- 端末へのアクセス( Ctrl + Alt + T 。
- テキストエディタ(Nanoやvi / vimなど)。
Bashで行ごとに読み取る
Bashを使用してファイルを1行ずつ読み取る方法はいくつかあります。次のセクションでは、Bashを使用してファイルを一度に1行ずつ処理する5つの方法について説明します。
方法1:読み取りコマンドとWhileループの使用
最初の方法は、読み取りコマンドと whileを使用することです。 Bashスクリプトでループします。ターミナルで同じことを行うことは可能ですが、Bashスクリプトはコードを保存して再利用可能にします。以下の手順に従ってください:
1.ターミナルを開きます( Ctrl + Alt + T )そして、vi / vimなどのテキストエディタを使用して新しいBashスクリプトを作成します:
vi line.sh2.次の行を入力します:
#!/bin/bash
file="days.txt"
while read -r line; do
echo -e "$line\n"
done <$file-
$file変数はシバン行(Bashスクリプトの最初の行)の後に定義され、処理する入力ファイルへのパスを格納します。
-
-rreadに追加された引数 コマンドは、ファイルの内容を読み取るときに円記号でエスケープされた文字が解釈されないようにします。
- 各行の内容は
$lineに保存されます 変数。while内 ループの場合、echoコマンドは$lineを出力します 変数の内容。-e引数はechoを許可します 改行文字などの特殊文字を解釈するには\n。
-
whileループは、ファイルの終わりに到達してループが終了するまで続きます。
3.スクリプトを保存して、viを終了します:
:wq4.スクリプトを実行します:
bash line.sh
スクリプトは、サンプルテキストファイルの各行を個別に出力します。
方法2:catコマンドとforループの使用
ファイルの内容を個々の行に表示する別の方法は、catコマンドと forを使用することです。 ループ。 for ループはechoを許可します catからの行を印刷します ファイルの終わりに達するまでコマンド出力。
以下の手順に従ってください:
1.新しいスクリプトを作成します:
vi readfile.sh2.次の行を入力します:
#!/bin/bash
file=$(cat days.txt)
for line in $file
do
echo -e "$line\n"
done-
$file変数は、catを使用して入力ファイルの内容を格納します コマンド。
-
forループはcatの各行を繰り返します コマンドを出力し、echoを使用して出力します ファイルの最後に到達するまでコマンドを実行します。
3.スクリプトを保存して、viを終了します:
:wq4.スクリプトを実行します:
bash readfile.sh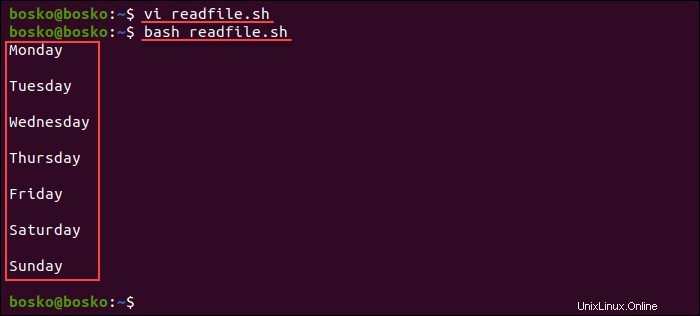
スクリプトは、ファイルの内容を標準出力で1行ずつ出力します。
方法3:ヒア文字列の使用
ファイルの内容を1行ずつ印刷する別の方法は、hereを使用することです。 ファイルの内容をreadにフィードする文字列 指図。 here stringは、 <<<の後に指定された変数、文字列、またはファイルの内容を接続します 呼び出されたプログラムの標準入力への構文。
以下の手順に従ってください:
1.新しいBashスクリプトを作成します:
vi herestrings.sh2.次の行を入力します:
#!/bin/bash
while IFS= read -r line; do
printf '%s\n' "$line"
done <<< $(cat days.txt )-
whileループ、IFS=引数は空白のトリミングを防ぐための空の文字列です。
-
-r引数は、円記号でエスケープされた文字の解釈を防ぎます。
-
printfコマンドは、ファイルの各行を出力します。フォーマット指定子は入力を文字列として扱います(%s)、改行文字を追加します(\n)各行の後。
here文字列はcatにフィードしますreadへのコマンドの出力 コマンド。
3.スクリプトを保存して、エディターを終了します。
:wq4.スクリプトを実行します:
bash herestrings.sh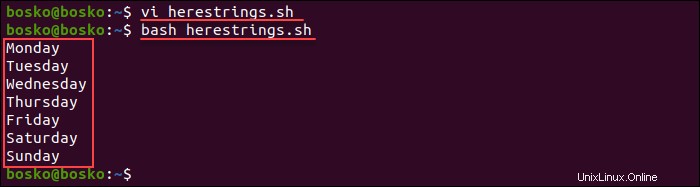
出力は、ファイルの内容を1行ずつ印刷します。
方法4:ファイル記述子の使用
ファイル記述子は、開いているファイルまたはプロセスを指します。各プロセスには、3つのデフォルトのファイル記述子があります。
-
0。標準入力。 -
1。標準出力。 -
2。標準エラー。
readの入力を提供します ファイル記述子を使用してコマンドを実行し、ファイルの内容から各行を個別に出力します。以下の手順に従ってください:
1.新しいbashスクリプトを作成します:
vi descriptors.sh2.次の行を入力します:
#!/bin/bash
while IFS= read -r -u9 line; do
printf '%s\n' "$line"
done 9< days.txt-
whileループし、readに指示します-uを指定して、ファイル記述子から入力を読み取るコマンド 引数とファイル記述子番号。
重要: ファイル記述子を指定するときは、内部シェルファイル記述子との競合を避けるために、4〜9の数字を使用してください。
-
printfコマンドは入力を処理します$line文字列としての変数(%s)そして改行文字を追加します(\n)$lineを印刷した後 内容。
-
9<構文には、whileと同じファイル記述子番号が含まれています ループ。入力ファイルの内容は、指定されたファイル記述子に送信されます。
3.スクリプトを保存します:
:wq4.スクリプトを実行して、コードをテストします。
bash descriptors.sh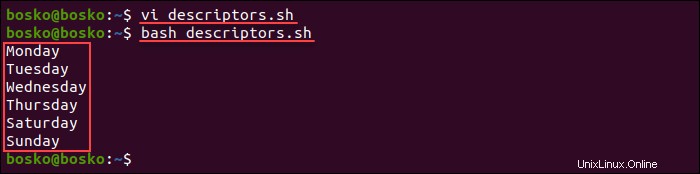
スクリプト出力は、ファイルの各行を個別に出力します。
方法5:プロセス置換の使用
プロセス置換により、1つまたは複数のプロセスの標準出力をファイルとして表示し、それを別のプロセスの標準入力にフィードできます。プロセス置換を使用して入力ファイルを提供し、各ファイル行を個別に印刷します。
以下の手順に従ってください:
1. Bashスクリプトを作成します:
vi substitution.sh2.次の行を入力します:
#!/bin/bash
while IFS= read -r line; do
printf '%s\n' "$line"
done < <(cat days.txt)- ループを閉じた後、
cat括弧で囲まれた入力ファイル<(cat [input_file_path]プロセス結果をreadに送信します コマンド。
重要: <の間に空白文字を追加しないように注意してください 文字と左括弧( 。空白文字を使用すると、コードがリダイレクトとして解釈され、エラーが発生します。
3.スクリプトを保存します:
:wq4.スクリプトを実行します:
bash substitution.sh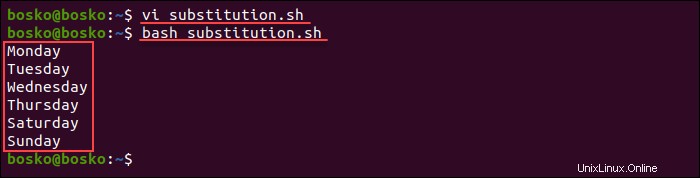
各ファイル行は、標準出力で個別に印刷されます。