ファイルシステムとは何ですか? Linuxの初期の寄稿者であり著者であるRobertLoveによると、「ファイルシステムは、特定の構造に準拠したデータの階層ストレージです」。ただし、この説明は、VFAT(仮想ファイルアロケーションテーブル)、Git、およびCassandra(NoSQLデータベース)にも同様に当てはまります。では、ファイルシステムの違いは何ですか?
Linuxカーネルでは、エンティティがファイルシステムであるためには、 open()も実装する必要があります。 、 read() 、および write() 名前が関連付けられている永続オブジェクトのメソッド。オブジェクト指向プログラミングの観点から、カーネルは汎用ファイルシステムを抽象インターフェースとして扱い、これらの大きな3つの関数は「仮想」であり、デフォルトの定義はありません。したがって、カーネルのデフォルトのファイルシステム実装は仮想ファイルシステム(VFS)と呼ばれます。
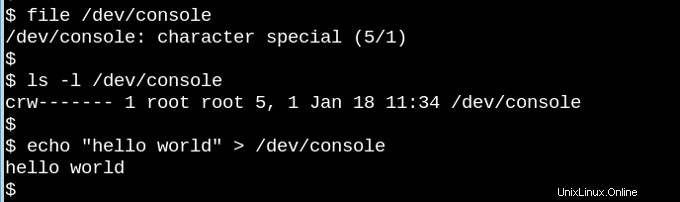
VFSは、Unixライクなシステムでは「すべてがファイルである」という有名な観察の根底にあります。上記の小さなデモでキャラクターデバイス/dev / console が登場するのは、どれほど奇妙なことか考えてみてください。 実際に動作します。この画像は、仮想テレタイプ(tty)でのインタラクティブなBashセッションを示しています。文字列を仮想コンソールデバイスに送信すると、仮想画面に表示されます。 VFSには、他にも奇妙な特性があります。たとえば、それらを探すことができます。
その他のLinuxリソース
- Linuxコマンドのチートシート
- 高度なLinuxコマンドのチートシート
- 無料のオンラインコース:RHELの技術概要
- Linuxネットワーキングのチートシート
- SELinuxチートシート
- Linuxの一般的なコマンドのチートシート
- Linuxコンテナとは何ですか?
- 最新のLinux記事
ext4、NFS、/ procなどの使い慣れたファイルシステムはすべて、file_operationsと呼ばれるC言語のデータ構造でビッグ3関数の定義を提供します。さらに、特定のファイルシステムは、使い慣れたオブジェクト指向の方法でVFS関数を拡張およびオーバーライドします。 Robert Loveが指摘しているように、VFSの抽象化により、Linuxユーザーは、内部データ形式を気にすることなく、外部のオペレーティングシステムやパイプなどの抽象エンティティとの間でファイルを簡単にコピーできます。ユーザースペースに代わって、システムコールを介して、プロセスは1つのファイルシステムのread()メソッドを使用してファイルからカーネルのデータ構造にコピーし、次に別の種類のファイルシステムのwrite()メソッドを使用してデータを出力できます。
VFS基本タイプ自体に属する関数定義は、カーネルソースのfs / *。cファイルにありますが、fs/のサブディレクトリには特定のファイルシステムが含まれています。カーネルには、cgroups、/ dev、tmpfsなどのファイルシステムのようなエンティティも含まれています。これらはブートプロセスの早い段階で必要であるため、カーネルのinit/サブディレクトリで定義されます。 cgroups、/ dev、およびtmpfsはfile_operationsのビッグ3関数を呼び出さず、代わりにメモリから直接読み取り、メモリに書き込むことに注意してください。
次の図は、ユーザースペースがLinuxシステムに一般的にマウントされているさまざまなタイプのファイルシステムにアクセスする方法を大まかに示しています。パイプ、dmesg、POSIXクロックなど、struct file_operationsも実装しているため、アクセスがVFSレイヤーを通過する構造体は示されていません。
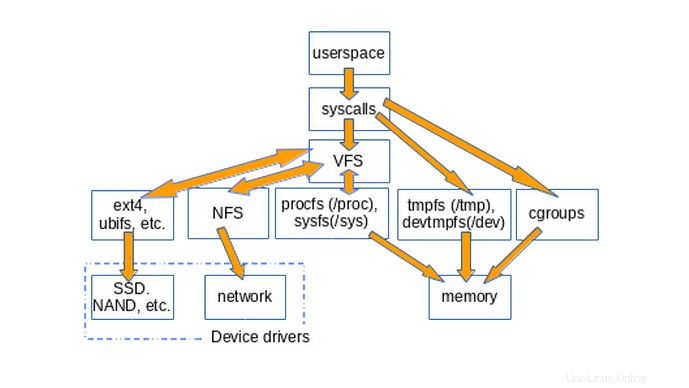
ファイルシステムに関連付けられた基本的なメソッドをすべてのファイルシステムタイプで再実装する必要がないため、VFSの存在はコードの再利用を促進します。コードの再利用は、広く受け入れられているソフトウェアエンジニアリングのベストプラクティスです。残念ながら、再利用されたコードが深刻なバグをもたらす場合、一般的なメソッドを継承するすべての実装がそれらのバグに苦しんでいます。
/ tmp:簡単なヒント
システムに存在するVFSを確認する簡単な方法は、mount|と入力することです。 grep -v sd | grep -v:/ 、これは、ディスク上に常駐せず、ほとんどのコンピューターのNFSではないマウントされたすべてのファイルシステムを一覧表示します。リストされているVFSマウントの1つは、確実に/ tmpになりますよね?

/ tmpをストレージに保持することが推奨されないのはなぜですか? / tmp内のファイルは一時(!)であり、ストレージデバイスはtmpfsが作成されるメモリよりも遅いためです。さらに、物理デバイスは、メモリよりも頻繁な書き込みによって摩耗しやすくなります。最後に、/ tmp内のファイルには機密情報が含まれている可能性があるため、再起動するたびにファイルを非表示にするのが機能です。
残念ながら、一部のLinuxディストリビューションのインストールスクリプトは、デフォルトでストレージデバイスに/tmpを作成します。これがあなたのシステムに当てはまるとしても、絶望しないでください。 tmpfsに割り当てられたメモリは他の目的には使用できないことに注意して、常に優れたArchWikiの簡単な手順に従って問題を修正してください。つまり、大きなファイルを含む巨大なtmpfsを含むシステムでは、メモリが不足してクラッシュする可能性があります。別のヒント:/ etc / fstabファイルを編集するときは、システムが起動しないため、必ず改行で終了してください。 (私がどのように知っているかを推測します。)
/procおよび/sys
/ tmpの他に、ほとんどのLinuxユーザーが最もよく知っているVFSは/procと/sysです。 (/ devは共有メモリに依存し、file_operationsはありません)。なぜ2つの味?もっと詳しく見てみましょう。
procfsは、カーネルの瞬間的な状態と、カーネルがユーザースペースに対して制御するプロセスのスナップショットを提供します。 / procで、カーネルは、割り込み、仮想メモリ、スケジューラなど、カーネルが提供する機能に関する情報を公開します。さらに、/ proc / sysは、sysctlコマンドを介して構成可能な設定にユーザースペースがアクセスできる場所です。個々のプロセスのステータスと統計は、/ proc/
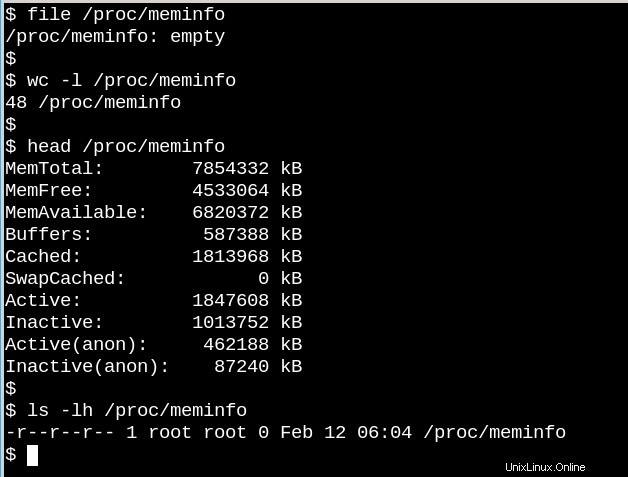
/ procファイルの動作は、ディスク上のファイルシステムとVFSがどのように異なるかを示しています。一方では、/ proc / meminfoには、コマンド freeによって提示される情報が含まれています。 。一方、それも空です!どうすればいいの?この状況は、1985年にコーネル大学の物理学者N. David Merminが書いた、「誰も見ていないときに月はそこにあるのか?現実と量子論」という有名な記事を彷彿とさせます。真実は、プロセスが/ procから要求したときにカーネルがメモリに関する統計を収集し、実際にはあるということです。 誰も見ていないときは、/procのファイルには何もありません。マーミンが言ったように、「測定が一般に、測定された特性の既存の値を明らかにしないことは、基本的な量子の教義です。」 (月についての質問への答えは演習として残されています。)

そこにある情報は動的であるため、procfsの明らかな空虚さは理にかなっています。 sysfsの状況は異なります。 /procと/sysに少なくとも1バイトのサイズのファイルがいくつあるかを比較してみましょう。
Procfsには正確に1つ、つまりエクスポートされたカーネル構成があります。これは、ブートごとに1回だけ生成する必要があるため、例外です。一方、/ sysには大きなファイルがたくさんあり、そのほとんどが1ページのメモリで構成されています。 / proc / meminfoのようなファイルを読み取ることによって生成される情報のテーブルとは対照的に、通常、sysfsファイルには正確に1つの数値または文字列が含まれます。
sysfsの目的は、カーネルが「kobjects」と呼ぶものの読み取り可能および書き込み可能なプロパティをユーザースペースに公開することです。 kobjectsの唯一の目的は参照カウントです。kobjectへの最後の参照が削除されると、システムはそれに関連付けられたリソースを再利用します。それでも、/ sysは、カーネルの有名な「ユーザースペースに対する安定したABI」のほとんどを構成しており、どのような状況でも「壊れ」ることはありません。これは、sysfs内のファイルが静的であることを意味するわけではなく、揮発性オブジェクトの参照カウントとは逆になります。
代わりに、カーネルの安定したABIは、できることを制約します。 / sysに表示されますが、特定の瞬間に実際に存在するものではありません。 sysfs内のファイルのアクセス許可を一覧表示すると、デバイス、モジュール、ファイルシステムなどの構成可能で調整可能なパラメーターを設定または読み取る方法がわかります。ロジックは、procfsもカーネルの安定したABIの一部であるという結論を強制しますが、カーネルのドキュメントにはそのように明示的に記載されていません。
eBPFおよびbccツールを使用したVFSのスヌーピング
カーネルがsysfsファイルを管理する方法を学ぶ最も簡単な方法は、実際の動作を監視することです。ARM64またはx86_64で監視する最も簡単な方法は、eBPFを使用することです。 eBPF(extended Berkeley Packet Filter)は、カーネル内で実行されている仮想マシンで構成されており、特権ユーザーはコマンドラインからクエリを実行できます。カーネルソースは、カーネルができることを読者に伝えます。 行う;起動したシステムでeBPFツールを実行すると、代わりにカーネルが実際に何をするかが表示されます 。
幸いなことに、eBPFの使用を開始するには、bccツールを使用すると非常に簡単です。bccツールは、主要なLinuxディストリビューションからパッケージとして入手でき、BrendanGreggによって十分に文書化されています。 bccツールは、Cの小さなスニペットが埋め込まれたPythonスクリプトです。つまり、どちらの言語にも慣れている人なら誰でも簡単に変更できます。この数では、bcc / toolsには80個のPythonスクリプトがあり、システム管理者または開発者が自分のニーズに関連する既存のスクリプトを見つける可能性が非常に高くなります。
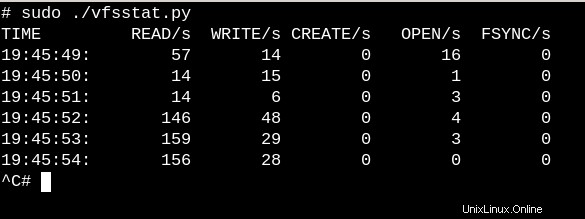
実行中のシステムでVFSが実行している作業について非常に大まかなアイデアを得るには、単純なvfscountまたはvfsstatを試してください。これは、vfs_open()とその友人への数十回の呼び出しが毎秒発生することを示しています。
ささいな例として、実行中のシステムにUSBスティックを挿入したときにsysfsで何が起こるかを見てみましょう。
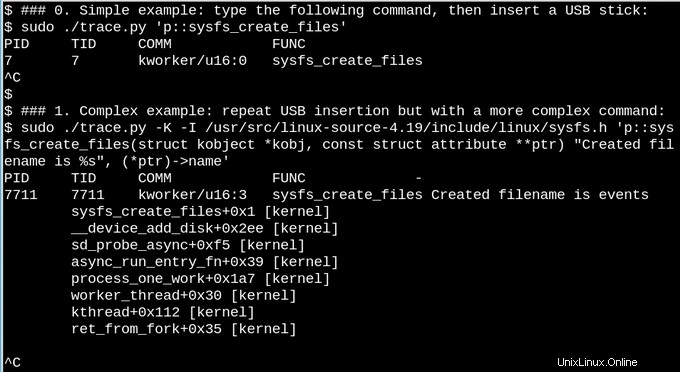
上記の最初の簡単な例では、trace.py bccツールスクリプトは、sysfs_create_files()コマンドが実行されるたびにメッセージを出力します。 sysfs_create_files()がUSBスティックの挿入に応答してkworkerスレッドによって開始されたことがわかりますが、どのファイルが作成されましたか? 2番目の例は、eBPFの全機能を示しています。ここで、trace.pyは、カーネルバックトレース(-Kオプション)とsysfs_create_files()によって作成されたファイルの名前を出力しています。一重引用符内のスニペットは、簡単に認識できるフォーマット文字列を含むCソースコードであり、提供されたPythonスクリプトは、LLVMジャストインタイムコンパイラをカーネル内仮想マシン内でコンパイルして実行するように誘導します。フォーマット文字列がパラメータの1つを参照できるように、完全なsysfs_create_files()関数シグネチャを2番目のコマンドで再現する必要があります。このCスニペットに誤りがあると、認識可能なCコンパイラエラーが発生します。たとえば、 -I パラメータを省略すると、「BPFテキストのコンパイルに失敗しました」という結果になります。 CまたはPythonのいずれかに精通している開発者は、bccツールを簡単に拡張および変更できることに気付くでしょう。
USBスティックを挿入すると、カーネルのバックトレースが表示され、PID7711がsysfsに「events」というファイルを作成したkworkerスレッドであることが示されます。 sysfs_remove_files()を使用した対応する呼び出しは、参照カウントの考え方に沿って、USBスティックを削除するとイベントファイルが削除されることを示しています。 USBスティックの挿入中にeBPFでsysfs_create_link()を見ると(図には示されていません)、48以上のシンボリックリンクが作成されていることがわかります。
とにかくイベントファイルの目的は何ですか? cscopeを使用して関数__device_add_disk()を見つけると、それがdisk_add_events()を呼び出していることがわかり、「media_change」または「eject_request」のいずれかがイベントファイルに書き込まれる可能性があります。ここで、カーネルのブロックレイヤーは、「ディスク」の出現と消滅についてユーザースペースに通知しています。 USBスティックの挿入がどのように機能するかを調査するこの方法が、ソースからのみプロセスを理解しようとするのと比較して、どれほど迅速に有益であるかを検討してください。
読み取り専用のルートファイルシステムにより、組み込みデバイスが可能になります
確かに、電源プラグを抜いてサーバーやデスクトップシステムをシャットダウンする人は誰もいません。なんで?物理ストレージデバイスにマウントされたファイルシステムには保留中の書き込みがある可能性があり、それらの状態を記録するデータ構造がストレージに書き込まれるものと同期しなくなる可能性があるためです。その場合、システム所有者は次の起動時にfsck filesystem-recoveryツールが実行されるのを待つ必要があり、最悪の場合、実際にデータが失われます。
それでも、愛好家は、ルーター、サーモスタット、自動車などの多くのIoTや組み込みデバイスが現在Linuxを実行していることを聞いたことがあるでしょう。これらのデバイスの多くはほとんど完全にユーザーインターフェイスを欠いており、それらをきれいに「アンブート」する方法はありません。 Linuxを実行しているヘッドユニットへの電力が繰り返し上下する、バッテリー切れの車をジャンプスタートすることを検討してください。エンジンが最終的に実行を開始したときに、長いfsckなしでシステムが起動するのはどうしてですか?答えは、組み込みデバイスは読み取り専用のルートファイルシステム(略してro-rootfs)に依存しているということです。
ro-rootfsには、不朽よりも明白ではない多くの利点があります。 1つは、Linuxプロセスが/usrまたは/libに書き込むことができない場合、マルウェアはそこに書き込むことができないということです。もう1つは、サポート担当者がフィールドのシステムと名目上同一のローカルシステムを所有しているため、リモートデバイスのフィールドサポートにはほとんど不変のファイルシステムが重要であるということです。おそらく最も重要な(しかし最も微妙な)利点は、ro-rootfsが開発者に、プロジェクトの設計段階でどのシステムオブジェクトを不変にするかを決定させることです。プログラミング言語のconst変数がしばしばそうであるように、ro-rootfsを扱うことはしばしば不便であるか、あるいは苦痛でさえあるかもしれません、しかし利点は余分なオーバーヘッドを簡単に返済します。
読み取り専用のrootfsを作成するには、組み込み開発者にとって追加の作業が必要です。そこでVFSが登場します。Linuxでは/ var内のファイルを書き込み可能にする必要があります。さらに、組み込みシステムが実行する多くの一般的なアプリケーションが構成を作成しようとします。 $HOME内のドットファイル。ホームディレクトリ内の構成ファイルの1つの解決策は、通常、それらを事前に生成し、rootfsにビルドすることです。 / varの場合、1つのアプローチは、/自体が読み取り専用としてマウントされている間に、別の書き込み可能なパーティションにマウントすることです。バインドマウントまたはオーバーレイマウントの使用は、もう1つの一般的な代替手段です。
マンマウントを実行しています バインドおよびオーバーレイマウントについて学ぶのに最適な場所です。これにより、組み込み開発者とシステム管理者は、1つのパスの場所にファイルシステムを作成し、それを2番目のパスの場所でアプリケーションに提供できます。組み込みシステムの場合、書き込み不可能なフラッシュデバイスの/ varにファイルを保存することは可能ですが、起動時にtmpfsのパスを/ varパスにオーバーレイまたはバインドマウントして、アプリケーションがそこを思いっきりスクロールできるようにします。喜び。次の電源投入時に、/varの変更はなくなります。オーバーレイマウントは、tmpfsと基盤となるファイルシステム間の結合を提供し、ro-rootfs内の既存のファイルに明らかな変更を加えることができます。一方、バインドマウントは、新しい空のtmpfsディレクトリをro-rootfsパスで書き込み可能として表示できます。 overlayfsは適切なファイルシステムタイプですが、バインドマウントはVFS名前空間機能によって実装されます。
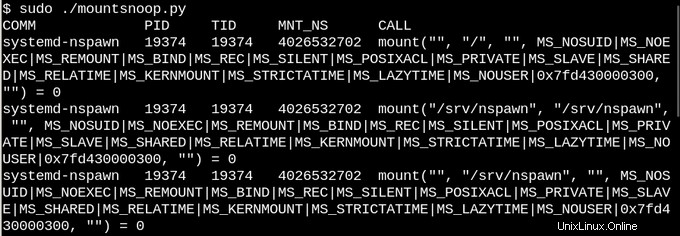
オーバーレイマウントとバインドマウントの説明に基づいて、Linuxコンテナーがそれらを多用していることに誰も驚かないでしょう。 systemd-nspawnを使用して、bccのmountsnoopツールを実行してコンテナーを起動するとどうなるかを調べてみましょう。

そして、何が起こったのか見てみましょう:
ここで、systemd-nspawnは、ホストのprocfsおよびsysfs内の選択されたファイルを、そのrootfs内のパスでコンテナーに提供しています。 bind-mountingを設定するMS_BINDフラグに加えて、「mount」システムコールが呼び出す他のフラグのいくつかは、ホスト名前空間とコンテナの変更間の関係を決定します。たとえば、bind-mountは、呼び出しに応じて、/procおよび/sysの変更をコンテナーに伝播するか、それらを非表示にすることができます。
Linuxの内部を理解することは不可能な作業のように思われるかもしれません。カーネル自体に膨大な量のコードが含まれており、LinuxユーザースペースアプリケーションとglibcなどのCライブラリのシステムコールインターフェイスは別としてです。進歩を遂げる1つの方法は、ユーザースペース向けのシステムコールとヘッダーに加えて、ここではfile_operationsテーブルで例示されている主要なカーネル内部インターフェイスを理解することに重点を置いて、1つのカーネルサブシステムのソースコードを読み取ることです。ファイル操作は「すべてがファイルである」ことを実際に機能させるものであるため、それらを処理することは特に満足のいくものです。トップレベルのfs/ディレクトリにあるカーネルCソースファイルは、仮想ファイルシステムの実装を構成します。仮想ファイルシステムは、一般的なファイルシステムとストレージデバイスの幅広く比較的簡単な相互運用性を可能にするシムレイヤーです。 Linux名前空間を介したバインドとオーバーレイのマウントは、コンテナーと読み取り専用のルートファイルシステムを可能にするVFSの魔法です。ソースコードの研究と組み合わせて、eBPFカーネル機能とそのbccインターフェースにより、カーネルのプローブがこれまでになく簡単になります。
コメントと訂正をしてくれたAkkanaPeckとMichaelEagerに感謝します。
Alison Chaikenが仮想ファイルシステムを紹介します。仮想ファイルシステムが必要な理由と、3月7〜10日にカリフォルニア州パサデナで開催される第17回Southern California Linux Expo(SCaLE 17x)でどのように機能するか