ハイブ データウェアハウスです Hadoopのモデル エコシステム。 Hadoop上でETLツールとして実行できます 。 Hiveで高可用性(HA)を有効にすることは、NamenodeやResourceManagerなどのマスターサービスで行う場合とは異なります。
Hiveでは自動フェイルオーバーは発生しません ( Hiveserver2 )。 Hiveserver2がある場合 ( HS2 )失敗し、失敗した HS2でジョブを実行します 失敗します。ジョブを他のHiveServer2で実行できるように、ジョブを再送信する必要があります 。したがって、 HAを有効にする HS2 HS2の数を増やすことに他なりません クラスターのコンポーネント 。
この記事では、高可用性をインストールして有効にする手順を説明します。 ハイブの 。
要件
- CentOS / RHEL 7にHadoopサーバーをデプロイするためのベストプラクティス–パート1
- Hadoopの前提条件の設定とセキュリティ強化–パート2
- CentOS / RHEL7にClouderaManagerをインストールして設定する方法–パート3
- CentOS / RHEL 7にCDHをインストールしてサービスプレースメントを構成する方法–パート4
- Namenodeの高可用性を設定する方法–パート5
- Resource Managerの高可用性を設定する方法–パート6
始めましょう…
Hiveのインストールと構成
1。 Cloudera Managerにログインします 以下のURLで、 Cloudera Managerに移動します –> サービスの追加 。
http://13.233.129.39:7180/cmf/home
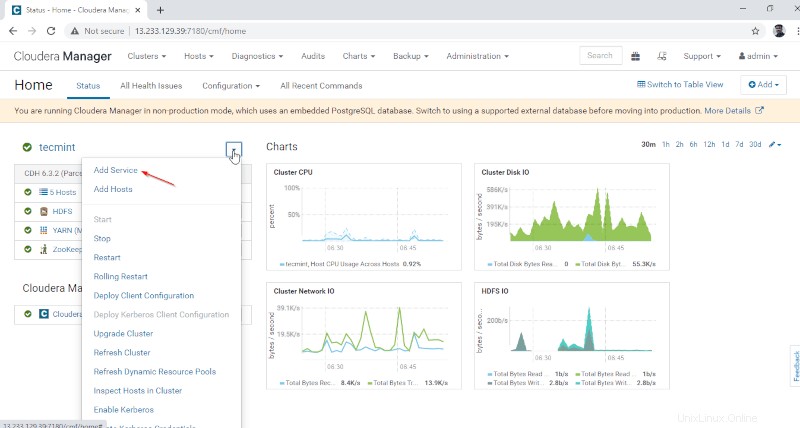
2。 サービス「ハイブ」を選択します ‘。
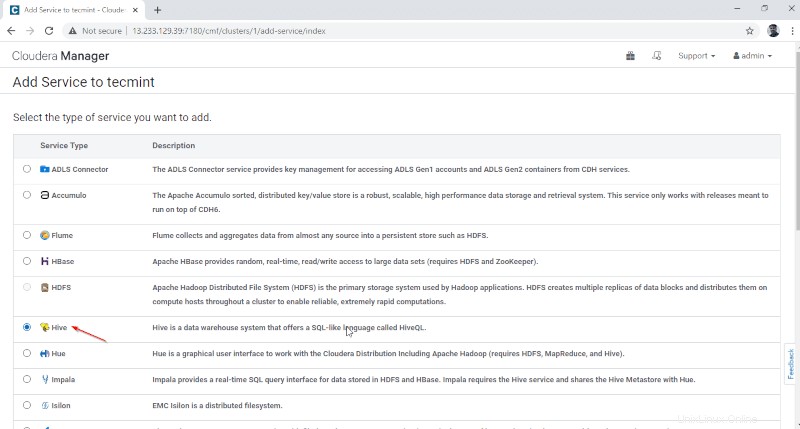
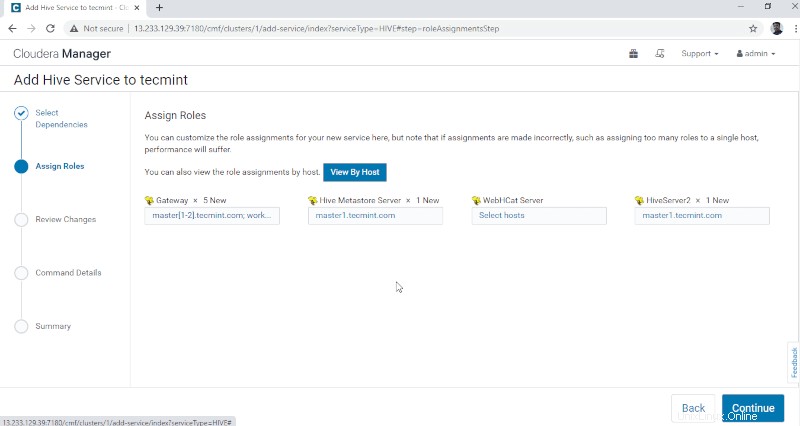
3。 ノードにサービスを割り当てます。
- ゲートウェイ –ユーザーがHiveにアクセスできるクライアントサービスです。通常、このサービスはエッジに配置されます ユーザー専用のノード。
- Hive Metastore –これはHiveメタデータを保存するための中央リポジトリです。
- WebHCatサーバー –これはHCatalogおよびその他のHadoopサービス用のWebAPIです。
- Hiveserver2 –これはHiveでクエリを実行するためのクライアントのインターフェースです。
サーバーを選択したら、[続行]をクリックします 「続行します。
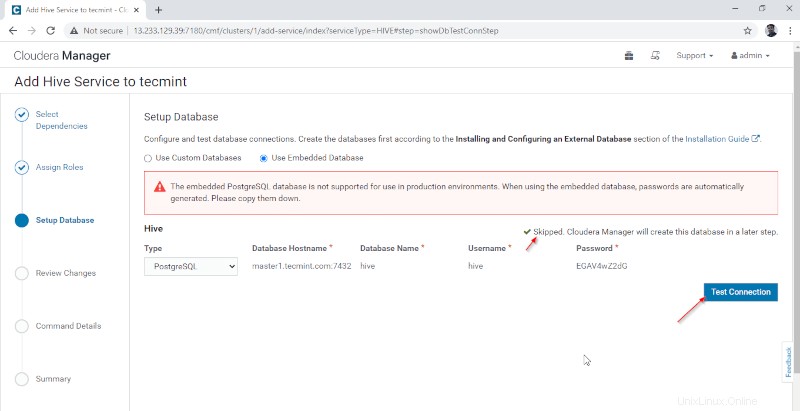
4。 Hive Metastoreには、メタデータを格納するための基盤となるデータベースが必要です。ここでは、デフォルトの PostgreSQLを使用しています CDHで構築されたデータベース 。
下記のデータベースの詳細が自動的に入力されます。「接続のテスト 上記のデータベースはオンザフライで作成されるため、’はスキップされます。リアルタイムで、外部データベースにデータベースを作成し、接続をテストしてさらに先に進む必要があります。完了したら、[続行]をクリックしてください ’。
5。 ハイブウェアハウスを構成します ディレクトリ、 / user / hive / Warehouse Hiveテーブルを保存するためのデフォルトのディレクトリパスです。 [続行]をクリックします ’。
6。 Hiveのインストールが開始されました。
7。 インストールが完了すると、「完了」を取得できます ' 状態。 [続行]をクリックします ’に進みます。
8。 Hiveのインストールと構成が正常に完了しました。 [完了]をクリックします ‘インストール手順を完了します。
9。 ハイブが表示されます クラスターに追加されたサービス ClouderaManagerダッシュボードから 。
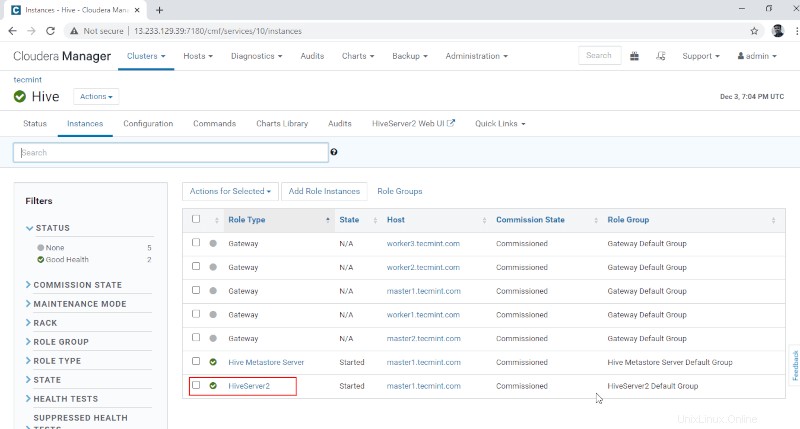
10。 Hiveserver2を表示できます インスタンス ハイブの 。 Hiveserver2を追加しました master1 。
Cloudera Manager –>ハイブ –>インスタンス –> Hiveserver2 。
Hiveでの高可用性の有効化
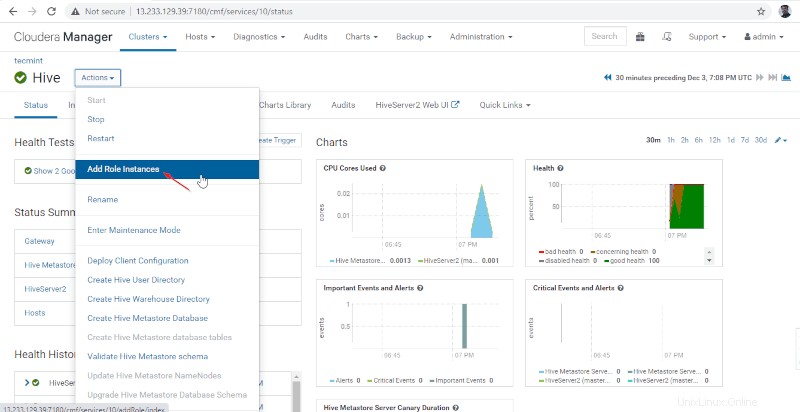
11。 次に、 Cloudera Manager に移動して、Hiveの役割を追加します –>ハイブ –>アクション –>役割の追加 インスタンス。
12。 追加のHiveserver2を配置するサーバーを選択します 。 2つ以上追加できます。制限はありません。ここでは、もう1つ Hiveserver2を追加しています。 master2 。
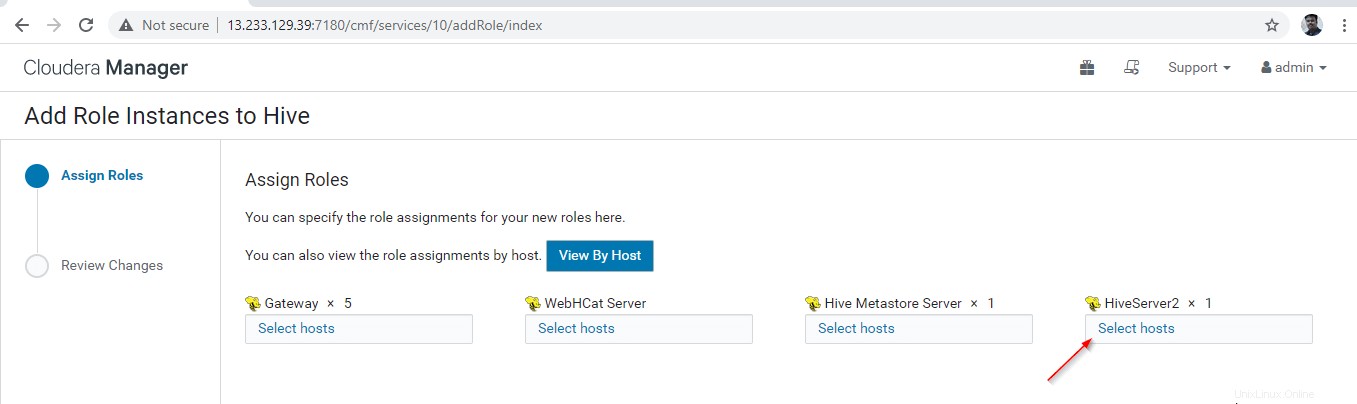
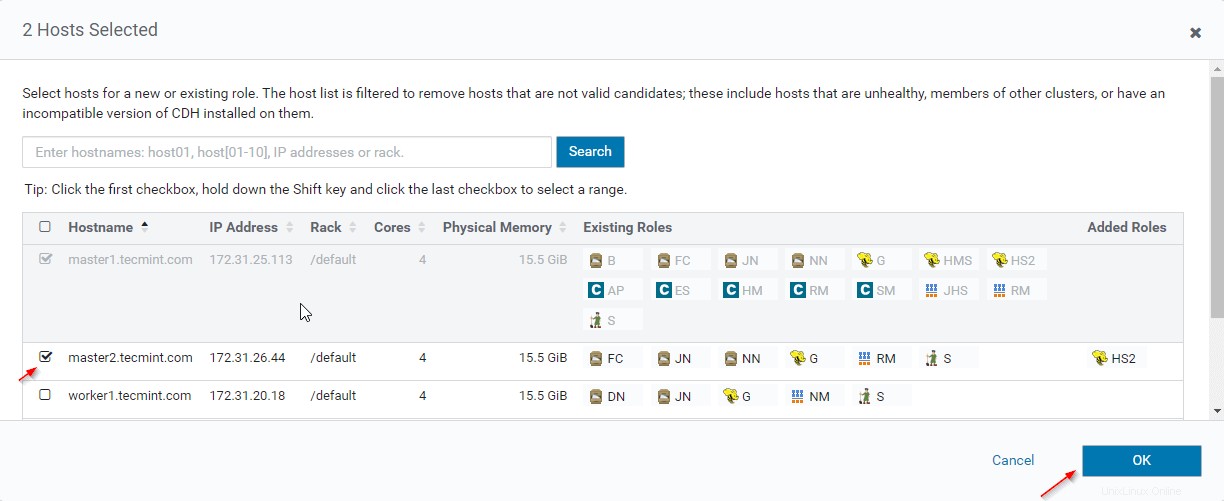
13。 サーバーを選択したら、[続行]をクリックします ’。
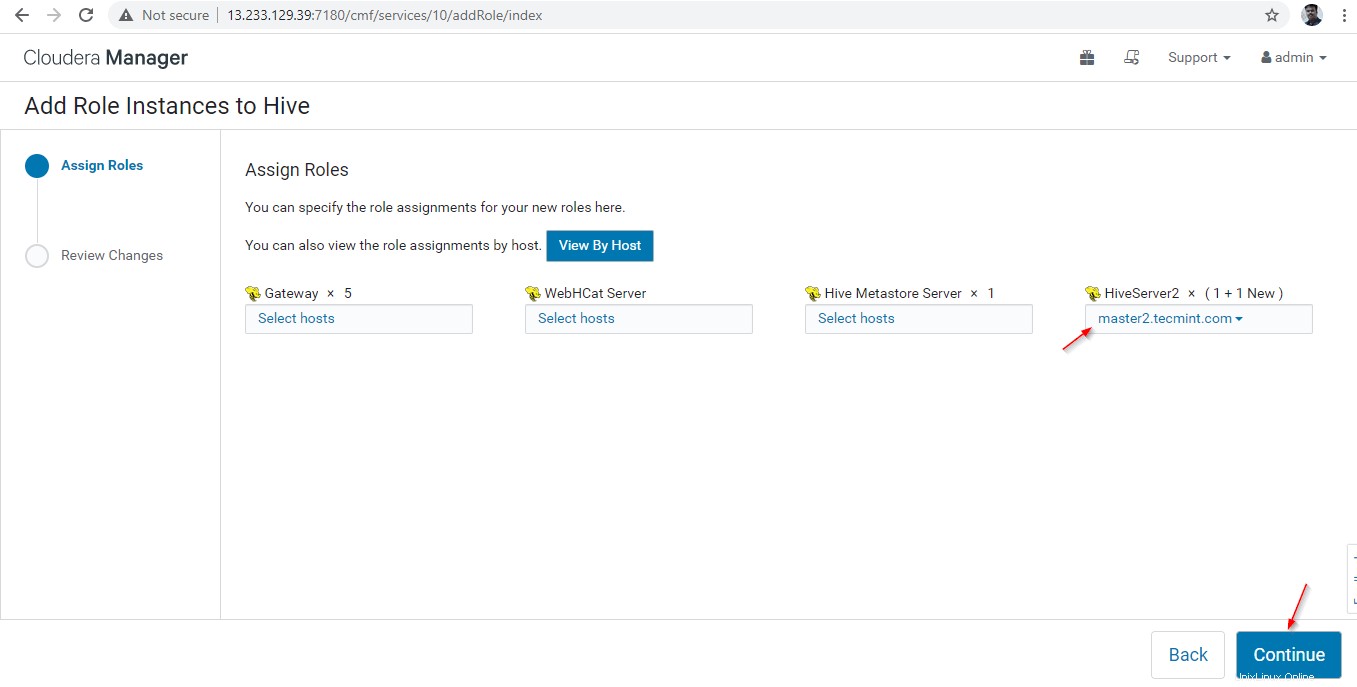
14。 Hiverserver2 ハイブインスタンスに追加されます 、 Cloudera Managerに移動して開始する必要があります –>ハイブ –>インスタンス –>(Hiveserver2を選択 新しく追加)–>選択したアクション –>開始 。
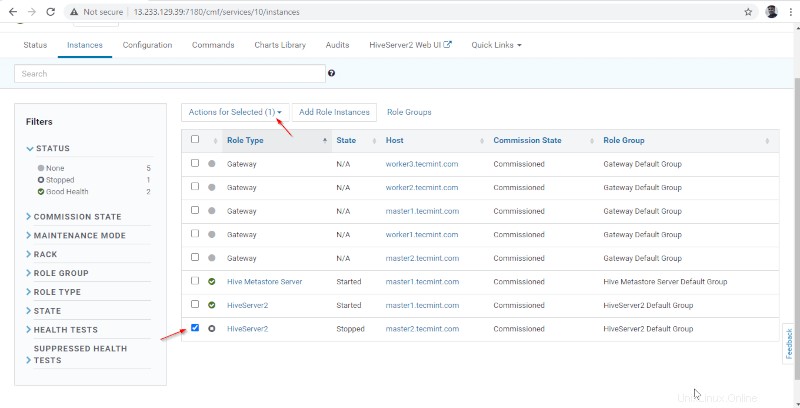
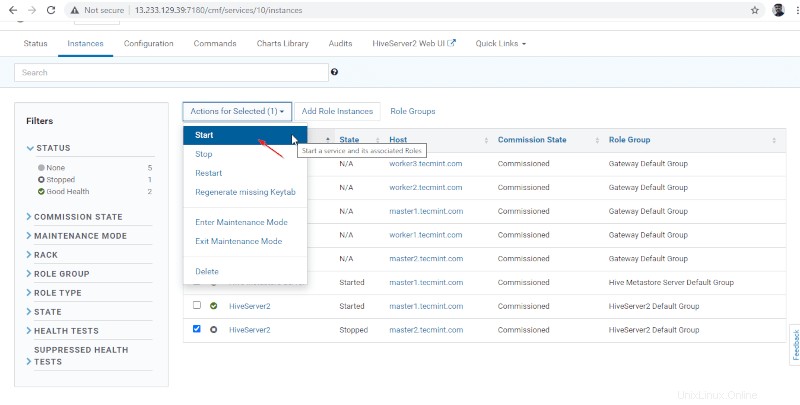
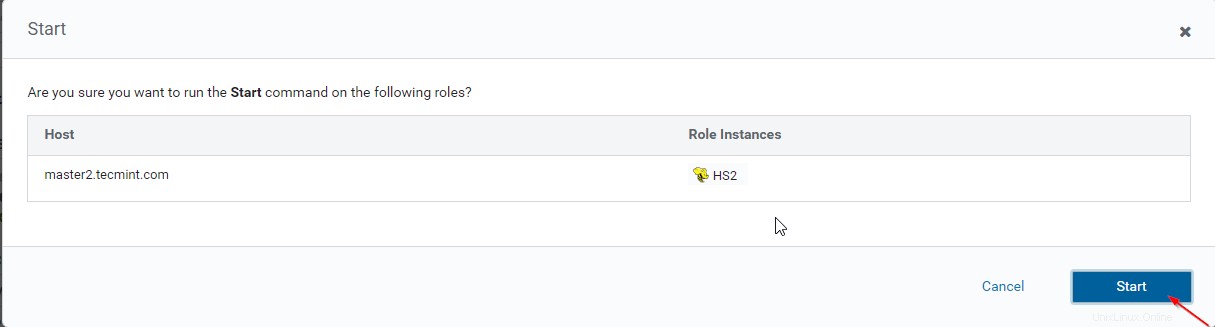
15。 一度Hiveserver2 master2で開始 、ステータスは「完了」になります ’。 閉じるをクリックします 。
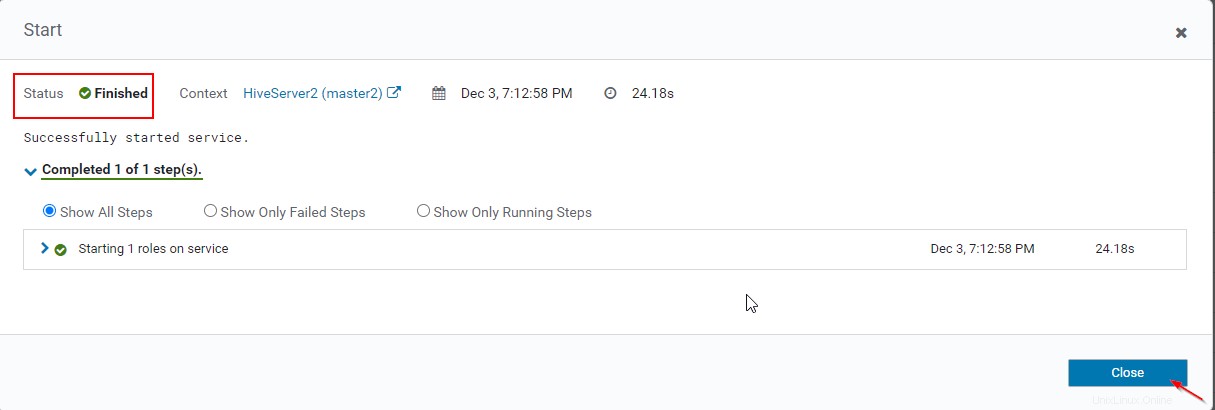
16。 Hiveserver2sの両方を表示できます 実行中です。
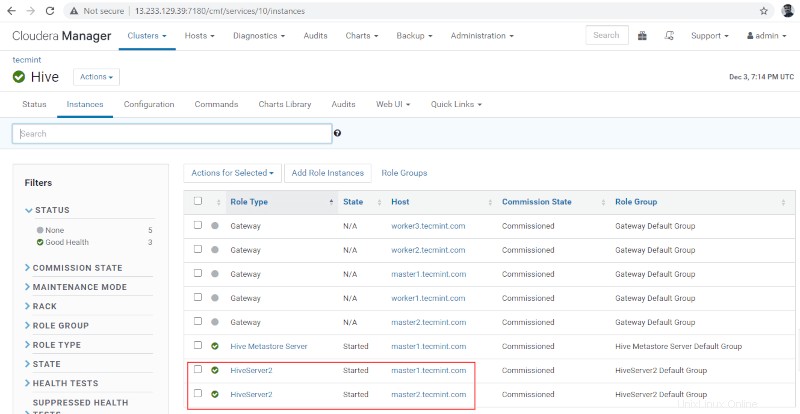
ハイブの可用性の確認
Hiveserver2を接続できます シンクライアントおよびコマンドラインであるbeelineを介して。 JDBCドライバーを使用して接続を確立します。
17。 Hive Gatewayがあるサーバーにログインします 実行中です。
[[email protected] ~]$ beeline

18。 JDBCを入力します Hiveserver2を接続するための接続文字列 。これに関連して、文字列 Hiverserver2について言及しています ( master2 )デフォルトのポート番号 10000 。この接続文字列は、 Hiveserver2にのみ接続します master2で実行されています 。
beeline> !connect "jdbc:hive2://master1.tecmint.com:10000"
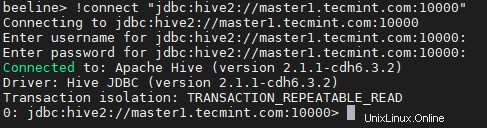
19。 サンプルクエリを実行します。
0: jdbc:hive2://master1.tecmint.com:10000> show databases;
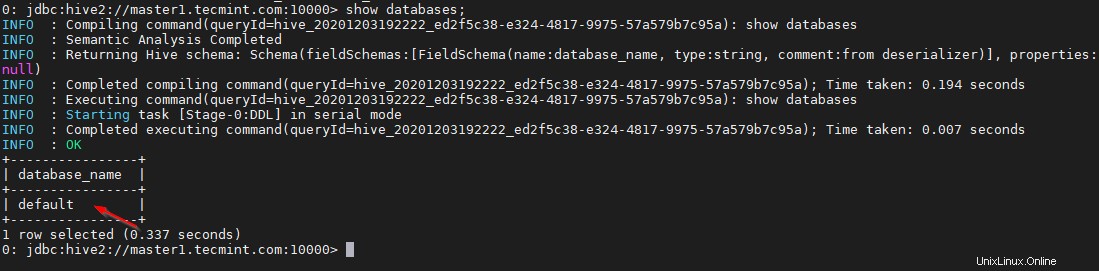
これは、組み込みのデフォルトのデータベースです。
20。 以下のコマンドを使用して、Hiveセッションを終了します。
0: jdbc:hive2://master1.tecmint.com:10000> !quit

21。 同じ方法でHiveserver2に接続できます master2で実行 。
beeline> !connect "jdbc:hive2://master2.tecmint.com:10000"
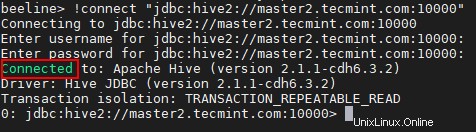
23。 Hiveserver2を接続できます Zookeeper Discovery モード。この方法では、 Hiveserver2について言及する必要はありません。 代わりに接続文字列でZookeeperを使用しています 利用可能なHiveserver2を見つける 。
ここでは、サードパーティのロードバランサーを使用して、使用可能な Hiverserver2間で負荷を分散できます。 。以下の構成は、ズームキーパー検出モードを有効にするために必要です。 Cloudera Managerに移動します –>ハイブ –>構成 。
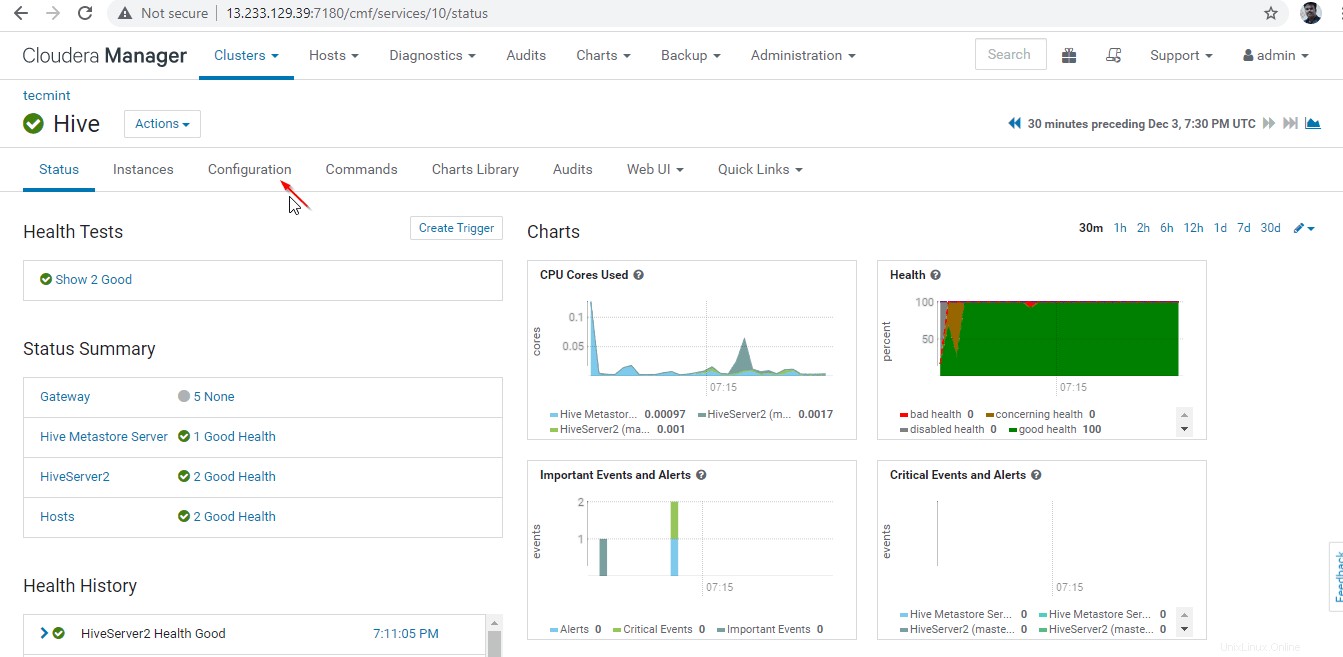
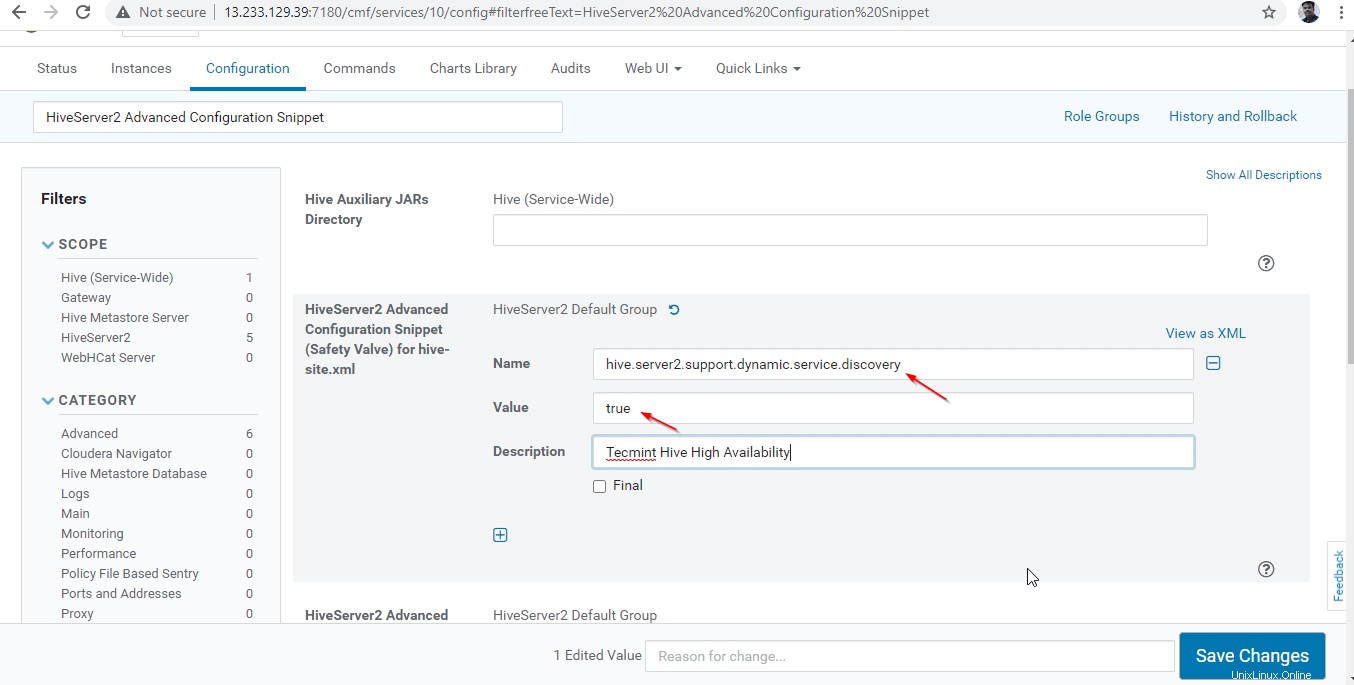
24。 次に、プロパティ「 HiveServer2 Advanced Configuration Snippet」を検索します 」をクリックし、+をクリックします 以下のプロパティを追加するための記号。
Name : hive.server2.support.dynamic.service.discovery Value : true Description : <any description>
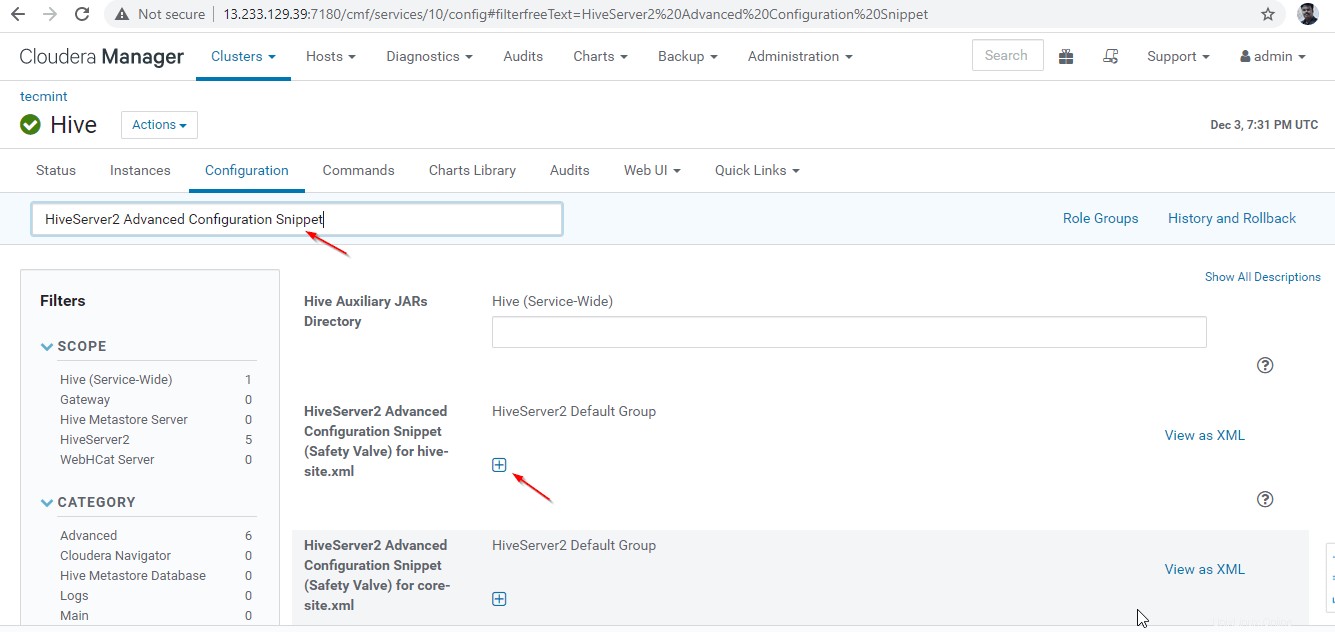
25。 プロパティを入力したら、[変更を保存]をクリックします ’。
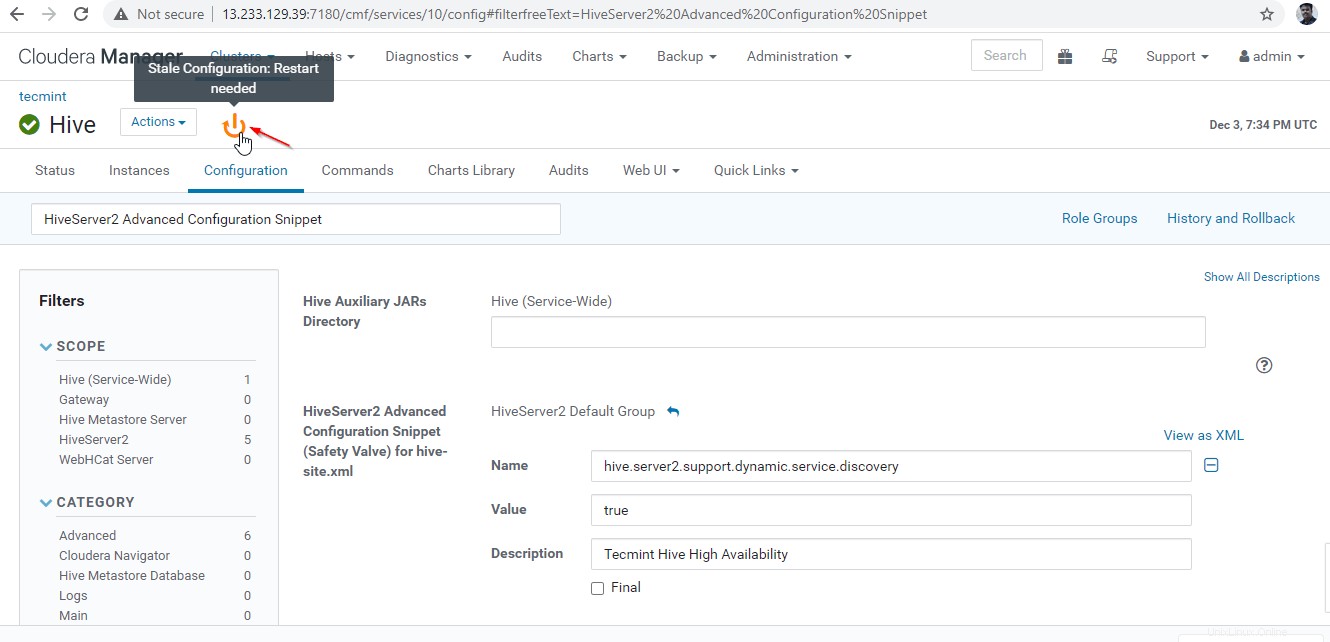
26。 構成を変更したので、オレンジ色の記号をクリックして影響を受けるサービスを再起動し、サービスを再起動する必要があります。
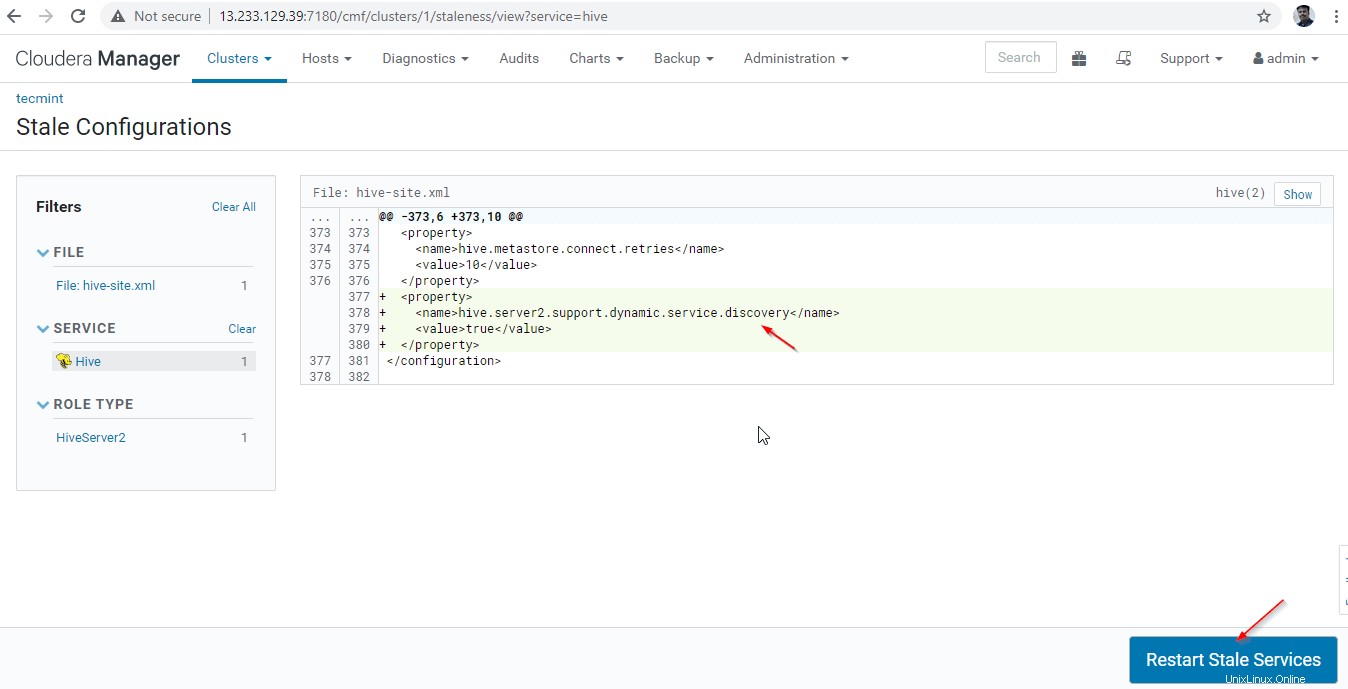
27。 [古いものを再起動]をクリックします ‘サービス。
28。 利用可能な2つのオプションがあります。クラスターが稼働中の場合は、停止を最小限に抑えるためにローリングリスタートを優先する必要があります。新しくインストールするので、2番目のオプション「クライアント構成の再デプロイ」を選択できます 」をクリックし、[今すぐ再起動]をクリックします ’。
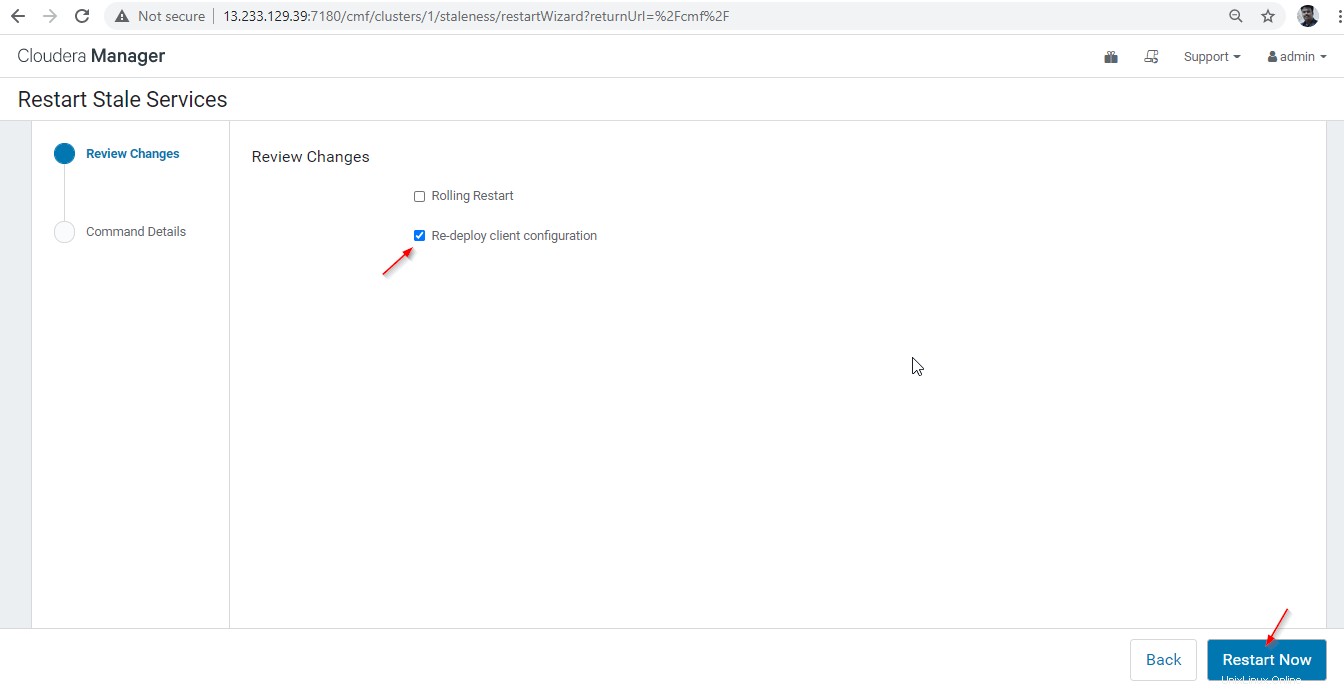
29。 再起動が正常に完了すると、ステータスが「完了」になります。 ’。 [完了]をクリックします ’でプロセスを完了します。
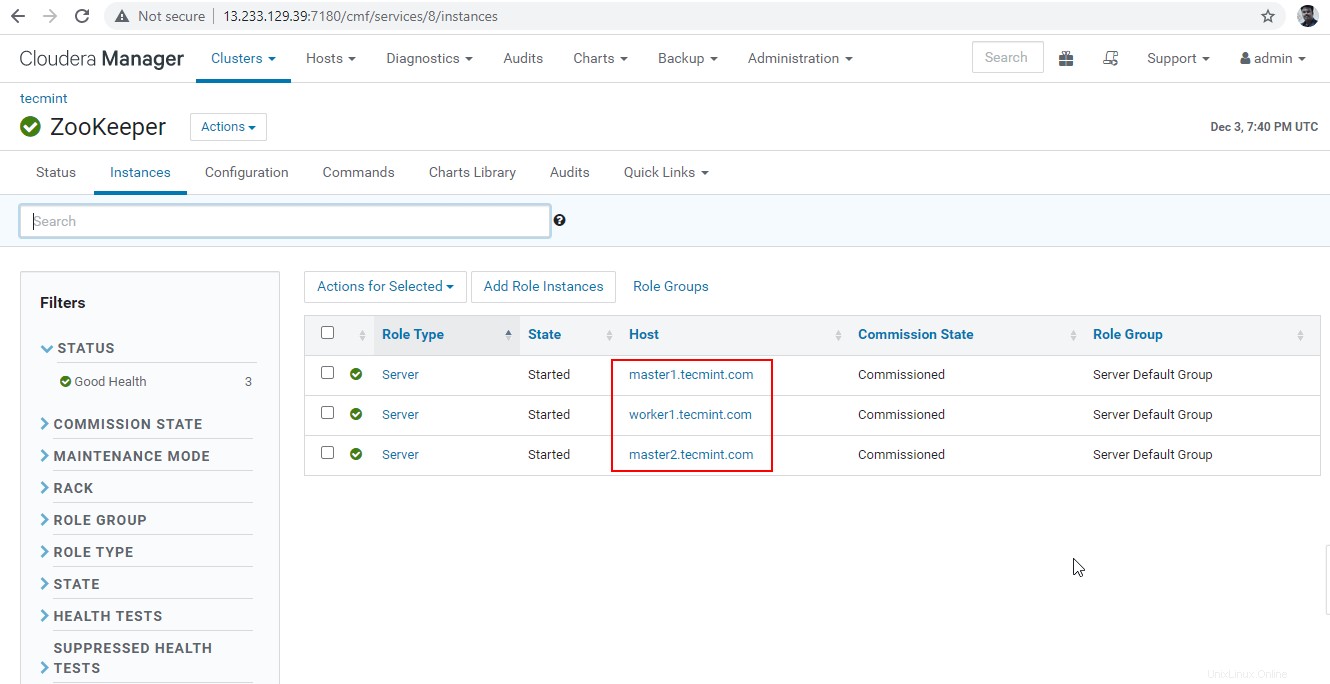
30。 次に、 Hiveserver2を接続します Zookeeper Discoveryを使用する モード。 JDBC 接続、 Zookeeperを使用するために必要な文字列 ポート番号が2081のサーバー 。 Cloudera Manager に移動して、Zookeeperサーバーを収集します –>ズーキーパー –>インスタンス –>(サーバー名を書き留めます)。
これらはZookeeperを備えた3つのサーバーであり、2181はポート番号です。
master1.tecmint.com:2181 master2.tecmint.com:2181 worker1.tecmint.com:2181
31。 次に、ビーラインに入ります 。
[[email protected] ~]$ beeline

32。 JDBCを入力します 下記の接続文字列。 サービス検出モードについて言及する必要があります およびZookeeper名前空間 。 ‘ hiveserver2 ’はHiveserver2のデフォルトの名前空間です。
beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2">

33。 これで、セッションは Hiveserver2に接続されました master1で実行 。サンプルクエリを実行して検証します。以下のコマンドを使用してデータベースを作成します。
0: jdbc:hive2://master1.tecmint.com:2181,mast> create database tecmint;

34。 以下のコマンドを使用して、データベースを一覧表示します。
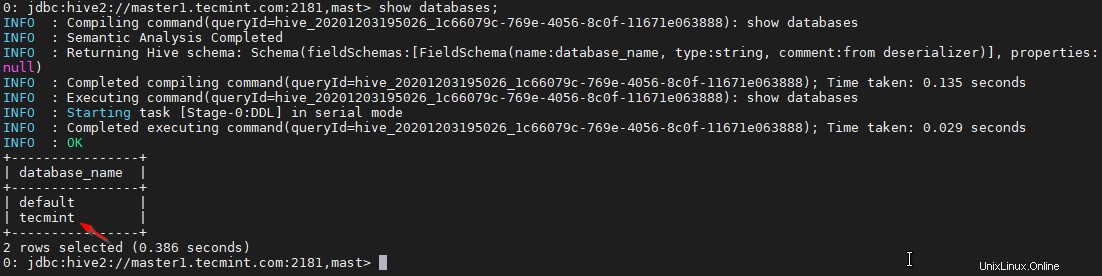
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
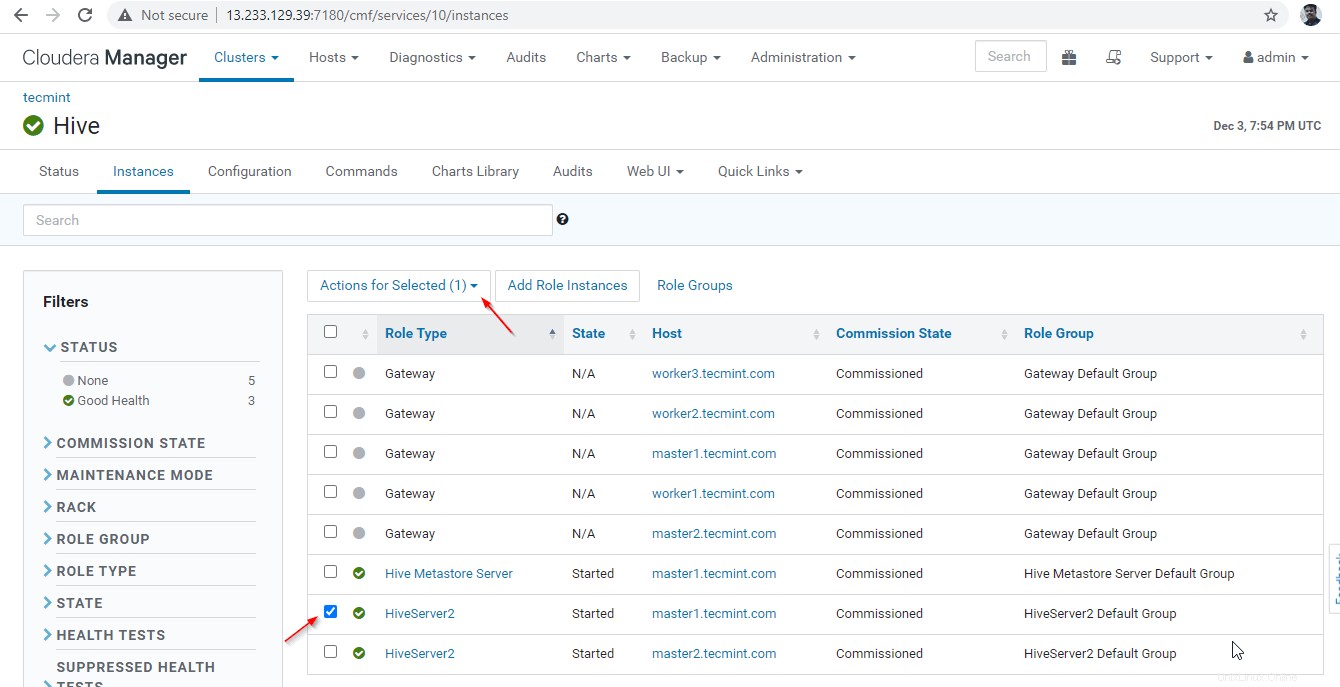
35。 次に、ズームキーパー検出モードでの高可用性を検証します 。 Cloudera Managerに移動します Hiveserver2を停止します master1 上記でテストしたこと。
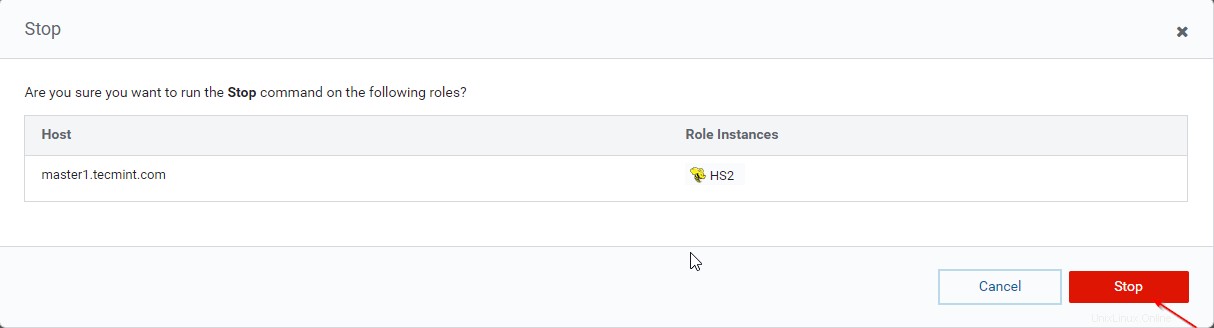
Cloudera Manager –>ハイブ –>インスタンス –>( Hiveserver2を選択します master1 )–>選択したアクション –>停止 。
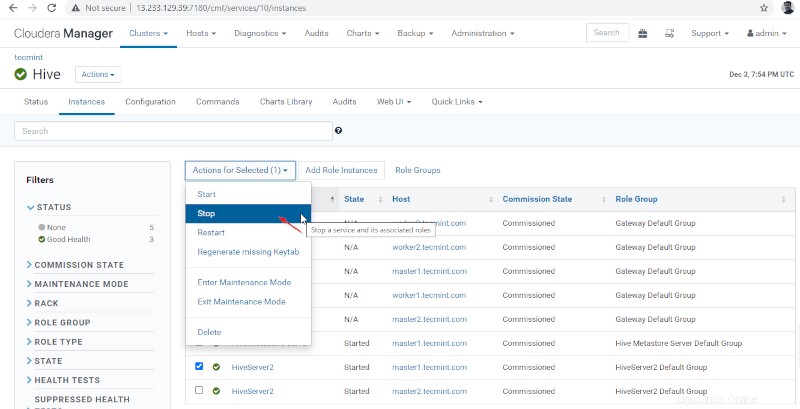
36。 [停止]をクリックします ’。停止すると、ステータスが「終了」になります ’。 Hiveserver2を確認します master1 ハイブに移動します –>インスタンス 。
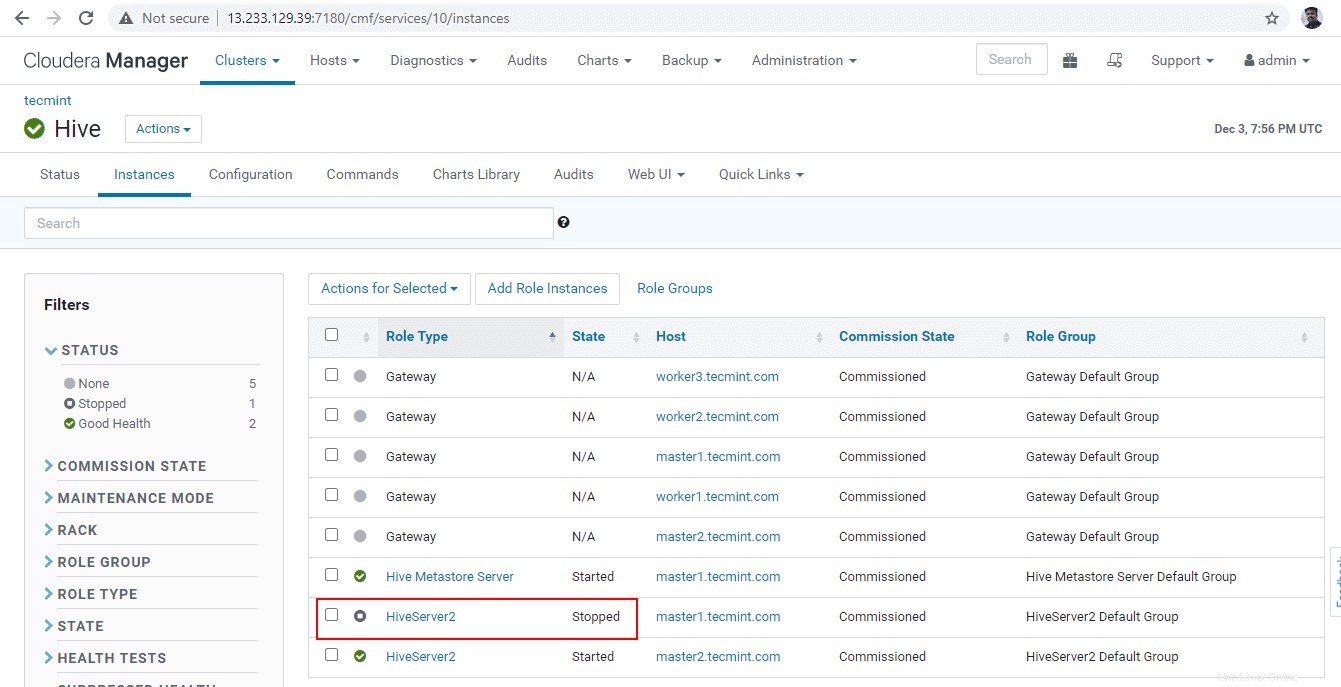
37。 ビーラインに入る Hiveserver2を接続します 同じJDBCを使用する ズームキーパー検出モードの接続文字列 上記の手順で行ったように。
[[email protected] ~]$ beeline beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

これで、 Hiveserver2に接続されます master2で実行 。
38。 サンプルクエリで検証します。
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
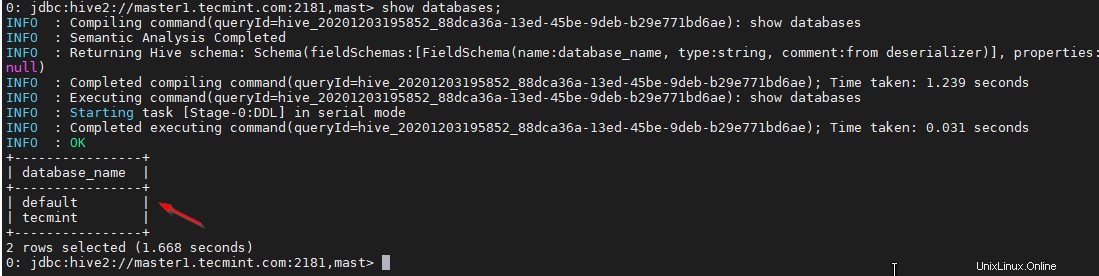
結論
この記事では、Hiveデータウェアハウスを作成するための詳細な手順を実行しました。 クラスターのモデル 高可用性 。リアルタイムの本番環境では、3つ以上の Hiveserver2 ズームキーパー検出モードで配置されます 有効。
ここでは、すべてのHiveserver2の Zookeeperに登録しています 共通の名前空間の下 。 動的にズームキーパー 利用可能なHiveserver2を検出します ハイブセッションを確立します。