システム管理者にとって、入力または出力のリダイレクトを実行することは非常に一般的です。 その毎日の仕事中に。
入出力リダイレクトは非常に強力なツールであり、複数のコマンドを接続したり、複数のコマンドの出力を合成したりすることができます。
入力/出力リダイレクト はUnixベースのシステムのコアコンセプトであり、プログラマーの生産性を向上させる方法として使用できます。 ものすごい。
ただし、入力と出力のリダイレクトは大きな問題であり、生産性を高めるために理解する必要のある基本事項がいくつかあります。
このチュートリアルでは、すべてを理解します。 Linuxシステムでの入力と出力のリダイレクトについて知っておく必要があること。
Linuxカーネルの設計について考察します。 入力と出力のリダイレクトとは何かを深く完全に理解するために、ファイルとプロセスの動作方法について説明します。
理論的な知識が実践的な演習とリンクしていることを確認するために、途中でいくつかの例が提供されます。
準備はいいですか?
何を学ぶか
このチュートリアルを最後まで実行すると、次の概念について学ぶことができます。
- どのファイル記述子 標準の入力と出力との関係;
- 標準の入力と出力を確認する方法 Linux上の特定のプロセスについて;
- 標準の入力と出力をリダイレクトする方法 Linuxの場合;
- パイプラインを使用する方法 長いコマンドの入力と出力を連鎖させるため。
これは非常に長いプログラムですが、これ以上面倒なことはしません。ファイル記述子とは何か、Linuxカーネルによってファイルがどのように概念化されているかを見てみましょう。
1 – Linuxプロセスとは何ですか?
Linuxシステムでの入出力を理解する前に、Linuxプロセスとは何か、およびそれらがハードウェアとどのように相互作用するかについて、いくつかの基本を理解することが非常に重要です。
入力および出力リダイレクトコマンドラインのみに関心がある場合は、次のセクションにジャンプできます。このセクションは、このテーマをさらに深く掘り下げていくシステム管理者を対象としています。
a – Linuxプロセスはどのように作成されますか?
かなり人気のある格言なので、おそらく以前に聞いたことがあるでしょうが、Linuxではすべてがファイルです 。
これは、プロセス、デバイス、キーボード、ハードドライブがファイルシステム上に存在するファイルとして表されることを意味します。
Linuxカーネルは、ファイルタイプを割り当てることにより、これらのファイルを区別する場合があります。 (ファイル、ディレクトリ、ソフトリンク、ソケットなど)が、カーネルによって同じデータ構造に格納されます。
ご存知かもしれませんが、Linuxプロセスは、既存のプロセスのフォークとして作成されます。既存のプロセスは、最近のディストリビューションではinitプロセスまたはsystemdプロセスである可能性があります。
新しいプロセスを作成するとき、Linuxカーネルは親プロセスをフォークし、次の構造を複製します。
b – Linuxではファイルはどのように保存されますか?
ダイアグラムは100語を話すと思うので、Linuxシステムでファイルを概念的に保存する方法は次のとおりです。

ご覧のとおり、作成されたプロセスごとに、新しい task_struct Linuxホスト上に作成されます。
この構造には2つの参照があり、1つはファイルシステムメタデータ( fs と呼ばれます)用です。 )たとえば、ファイルシステムマスクなどの情報を見つけることができます。
もう1つは、ファイル記述子と呼ばれるものを保持するファイルの構造です。 。
メタデータも含まれています プロセスで使用されるファイルについてですが、この章ではファイル記述子に焦点を当てます。
コンピュータサイエンスでは、ファイル記述子は、カーネル自体によって現在使用されている他のファイルへの参照です。
しかし、それらのファイルは何を表していますか?
c – Linuxでファイル記述子はどのように使用されますか?
おそらくすでにご存知のように、カーネルは anとして機能します ハードウェアデバイス間のインターフェース (画面、マウス、CD-ROM、またはキーボード)。
これは、カーネルが、ディスク間でいくつかのファイルを転送したい、またはたとえばセカンダリドライブに新しいビデオを作成したいということを理解できることを意味します。
その結果、Linuxカーネルはデータを入力デバイス(キーボードなど)から出力デバイス(ハードドライブなど)に永続的に移動しています。
この抽象化を使用すると、プロセスは本質的に入力を操作する方法です (読む 操作)さまざまな出力をレンダリングします(書き込みとして) 操作)
しかし、どのように処理するかで、データの送信先を知ることができますか?
プロセスは、ファイル記述子を使用してデータの送信先を認識しています。
Linuxでは、ファイル記述子0(またはfd [0]) 標準入力に割り当てられます。
同様にファイル記述子1(またはfd [1]) 標準出力に割り当てられます 、およびファイル記述子2(またはfd [2]) 標準エラーに割り当てられます
これはLinuxシステムでは定数であり、すべてのプロセスで、最初の3つのファイル記述子は標準の入力、出力、およびエラー用に予約されています。
これらのファイル記述子は、Linuxシステム上のデバイスにマップされます。
カーネルがインスタンス化されたときに登録されたデバイスは、 / devで確認できます。 ホストのディレクトリ。
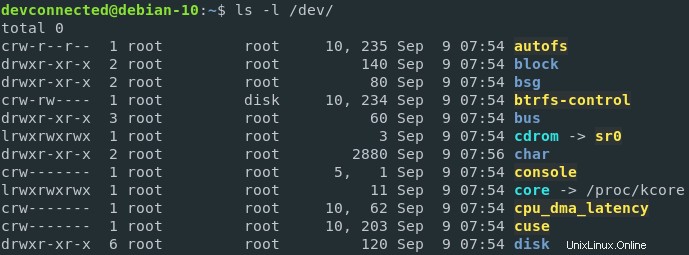
特定のプロセスのファイル記述子、たとえばbashプロセスを見ると、ファイル記述子は基本的にホスト上の実際のハードウェアデバイスへのソフトリンクであることがわかります。
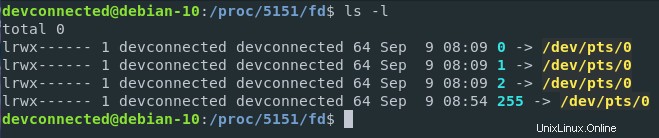
ご覧のとおり、bashプロセスのファイル記述子(ホスト上に5151 PIDがある)を分離すると、デバイスがプロセス(またはプロセス用にカーネルによって開かれたファイル)と対話しているのを確認できます。
この場合、 / dev / pts / 0 仮想ファイルシステム上の仮想デバイス(またはtty)である端末を表します。簡単に言うと、bashインスタンス(Gnomeターミナルインターフェイスで実行)がキーボードからの入力を待機し、画面に出力して、要求されたときに実行することを意味します。
ファイル記述子とそれらがプロセスでどのように使用されるかをより明確に理解したので、Linuxで入力と出力のリダイレクトを行う方法について説明する準備が整いました。 。
2 – Linuxでの出力リダイレクトとは何ですか?
入出力リダイレクトは、リダイレクト/変更するために使用される手法です。 標準の入力と出力。基本的に、データの読み取り場所または書き込み場所を変更します。
たとえば、Linuxシェルでコマンドを実行すると、出力が端末に直接出力される場合があります(たとえば、catコマンド)。
ただし、出力リダイレクトを使用すると、catコマンドの出力をファイルに保存して長期保存することもできます。
a –出力リダイレクトはどのように機能しますか?
出力リダイレクトとは、プロセスの出力を、ファイル、データベース、端末、または書き込み可能なデバイス(または仮想デバイス)などの選択した場所にリダイレクトすることです。
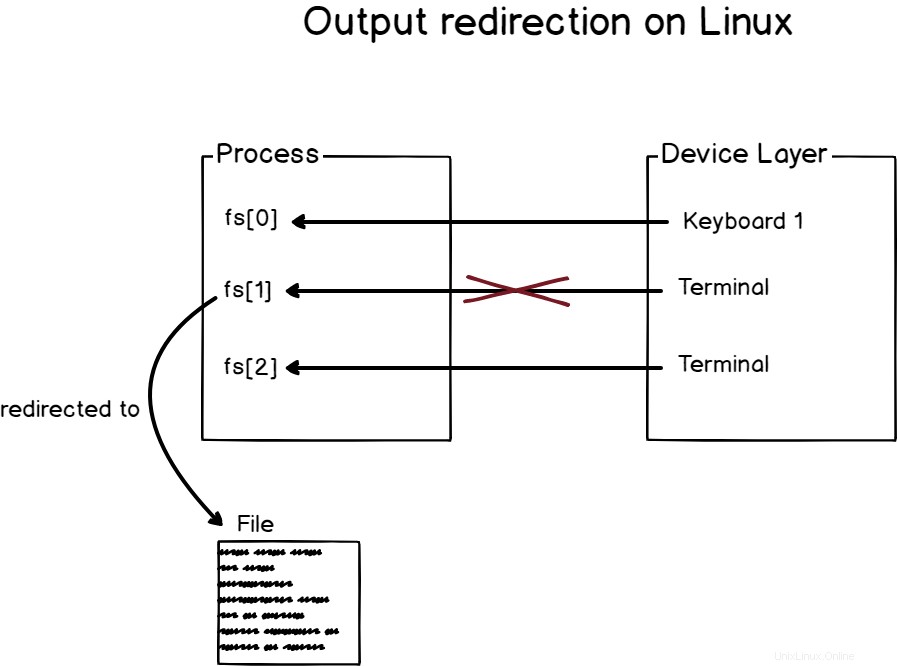
例として、echoコマンドを見てみましょう。
デフォルトでは、echo関数は文字列パラメーターを受け取り、それをデフォルトの出力デバイスに出力します。
結果として、エコー機能を実行する場合、出力は端末自体に出力されます。

ここで、長期保存のために、代わりに文字列をファイルに出力したいとします。
Linuxで標準出力をリダイレクトするには、「>」演算子を使用する必要があります。
例として、echo関数の標準出力をファイルにリダイレクトするには、
を実行する必要があります。$ echo devconnected > fileファイルが存在しない場合は、作成されます。
次に、ファイルの内容を確認して、「devconnected」文字列が正しく印刷されていることを確認できます。

または、「 1>」を使用して出力をリダイレクトすることもできます。 」構文。
$ echo test 1> file
b –非破壊的な方法でファイルへの出力リダイレクト
標準出力をファイルにリダイレクトすると、ファイルの既存のコンテンツが消去されることに気づいたかもしれません。
ファイルの既存のコンテンツを保持し、ファイルの最後にいくつかの変更を追加するだけであるため、非常に問題になる場合があります。
出力リダイレクトを使用してファイルにコンテンツを追加するには、「>」演算子ではなく「>>」演算子を使用します。
前に使用した例を前提として、既存のファイルに2行目を追加しましょう。
$ echo a second line >> file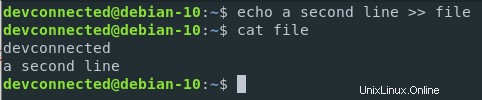
すばらしい!
ご覧のとおり、コンテンツは完全に上書きされるのではなく、ファイルに追加されました。
c –出力リダイレクトの落とし穴
出力リダイレクトを処理する場合、出力を同じファイルにリダイレクトするためだけに、ファイルに対してコマンドを実行したくなる場合があります。
同じファイルにリダイレクトする
echo 'This a cool butterfly' > file
sed 's/butterfly/parrot/g' file > fileテストファイルに何が表示されると思いますか?
その結果、ファイルは完全に空になります。

なぜですか?
デフォルトでは、コマンドを解析するとき、カーネルはコマンドを順番に実行しません。
これは、sedコマンドが終了して新しいファイルを開き、コンテンツを書き込むのを待たないことを意味します。
代わりに、カーネルはファイルを開き、その中のすべてのコンテンツを消去し、sed操作の結果が処理されるのを待ちます。
sed操作で空のファイルが表示されているため(出力リダイレクト操作によってすべてのコンテンツが消去されたため)、コンテンツは空です。
結果として、ファイルには何も追加されず、コンテンツは完全に空になります。
出力を同じファイルにリダイレクトするには、パイプを使用することをお勧めします または
などのより高度なコマンドcommand … input_file > temp_file && mv temp_file input_fileファイルが上書きされないように保護する
Linuxでは、「>」演算子によってファイルが上書きされないように保護することができます。
現在のシェル環境で「noclobber」パラメータを設定することで、ファイルを保護できます。
$ set -o noclobber出力リダイレクトを制限することも可能です。 実行することによって
$ set -C注 :出力リダイレクトを再度有効にするには、set + C
を実行するだけです。
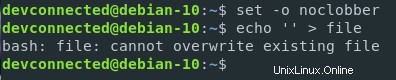
ご覧のとおり、このパラメータを設定するときにファイルを上書きすることはできません。
本当にオーバーライドを強制したい場合は、「> |」を使用できます 」演算子で強制します。

3 – Linuxでの入力リダイレクトとは何ですか?
a –入力リダイレクトはどのように機能しますか?
入力リダイレクトとは、プロセスの入力を特定のデバイス(または仮想デバイス)にリダイレクトして、カーネルによって割り当てられたデフォルトのデバイスからではなく、このデバイスからの読み取りを開始することです。
例として、ターミナルを開くときは、キーボードを使用してターミナルを操作しています。
ただし、プログラムでファイルのコンテンツをコマンドに送信したいため、ファイルのコンテンツを操作したい場合があります。
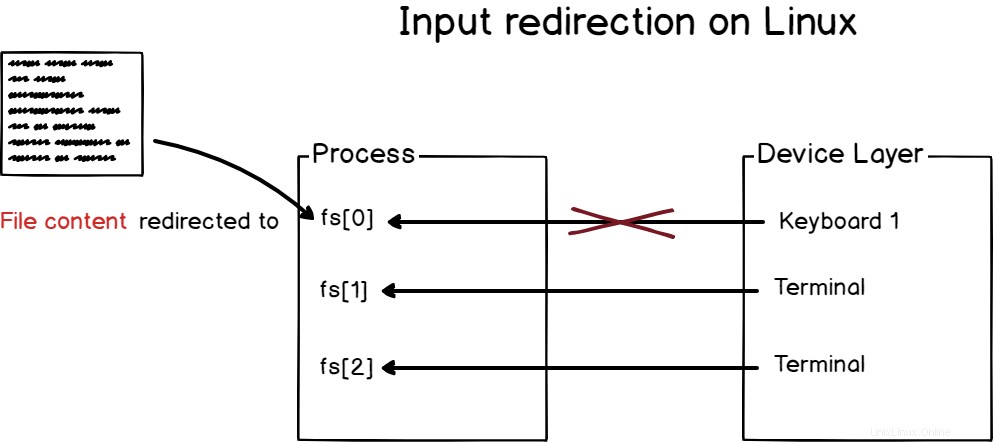
Linuxで標準入力をリダイレクトするには、「<」演算子を使用する必要があります。
例として、ファイルのコンテンツを使用して、それらに対して特別なコマンドを実行するとします。
この場合、ドメインを含むファイルを使用します。コマンドは単純な並べ替えコマンドになります。
このようにして、ドメインはアルファベット順にソートされます。
入力リダイレクトを使用すると、次のコマンドを実行できます
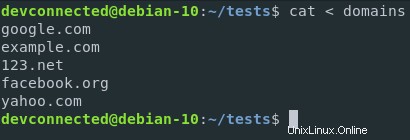
これらのドメインを並べ替える場合は、ドメインファイルのコンテンツを並べ替え機能の標準入力にリダイレクトできます。
$ sort < domains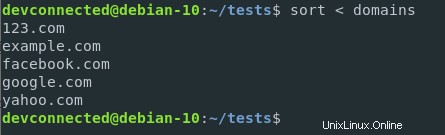
この構文では、ドメインファイルのコンテンツがsort関数の入力にリダイレクトされます。次の構文とはかなり異なります
$ sort domains出力が同じであっても、この場合、sort関数はファイルをパラメーターとして受け取ります。
入力リダイレクトの例では、並べ替え関数がパラメーターなしで呼び出されます。
結果として、関数にファイルパラメータが指定されていない場合、関数はデフォルトで標準入力からそれを読み取ります。
この場合、提供されたファイルの内容を読み取っています。
b –複数行を含むファイルで標準入力をリダイレクトする
ファイルに複数の行が含まれている場合でも、ファイルの1行ごとにコマンドからの標準入力をリダイレクトできます。
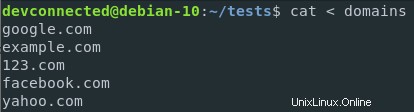
たとえば、ドメインファイル内のすべてのエントリに対してpingリクエストを送信したいとします。
デフォルトでは、pingコマンドは単一のIPまたはURLがpingされることを想定しています。
ただし、ドメインファイルのコンテンツを、すべてのエントリに対してping関数を実行するカスタム関数にリダイレクトすることはできます。
$ ( while read ip; do ping -c 2 $ip; done ) < ips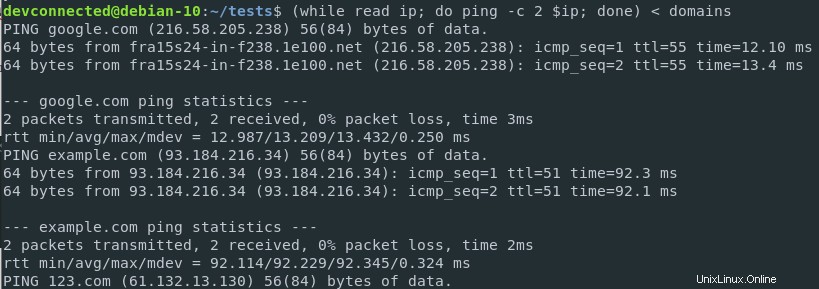
c –入力リダイレクトと出力リダイレクトの組み合わせ
標準の入力をコマンドにリダイレクトできることがわかったので、入力と出力のリダイレクトを同じコマンド内で実行できることに言及すると便利です。
pingコマンドを実行しているので、ドメインリストにあるすべてのWebサイトのping統計を取得しています。
結果は標準出力(この場合は端末)に出力されます。
しかし、結果をファイルに保存したい場合はどうでしょうか?
これは、同じコマンドで入力リダイレクトと出力リダイレクトを組み合わせることで実現できます。 。
$ ( while read ip; do ping -c 2 $ip; done ) < domains > stats.txt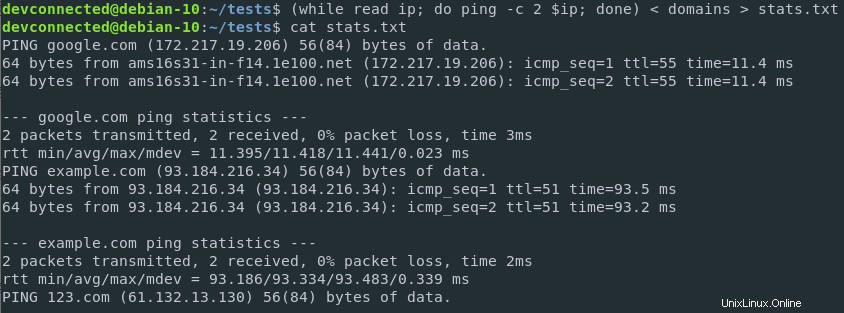
素晴らしい!
結果はファイルに正しく保存され、後で社内の他のチームが分析できます。
d –標準出力を完全に破棄する
場合によっては、標準出力を完全に破棄すると便利な場合があります。
プロセスの標準出力に関心がないか、このプロセスが標準出力に印刷する行が多すぎることが原因である可能性があります。
Linuxで標準出力を完全に破棄するには、標準出力を/ dev/nullにリダイレクトします。
/ dev / nullにリダイレクトすると、データは完全に破棄および消去されます。
$ cat file > /dev/null注:/ dev / nullにリダイレクトしても、ファイルの内容は消去されませんが、標準出力の内容のみが破棄されます。
4 – Linuxでの標準エラーリダイレクトとは何ですか?
最後に、入力と出力のリダイレクト後、標準エラーをリダイレクトする方法を見てみましょう。
a –標準エラーリダイレクトはどのように機能しますか?
以前に見たものと非常によく似ていますが、エラーリダイレクトは、プロセスによって返されたエラーをホスト上の定義されたデバイスにリダイレクトします。
たとえば、不正なパラメータを使用してコマンドを実行している場合、画面に表示されるのはエラーメッセージであり、エラーメッセージの原因となるファイル記述子を介して処理されています(fd [2])。>
エラーメッセージを端末の標準出力メッセージと区別する簡単な方法はないことに注意してください。プログラマーがエラーメッセージを正しいファイル記述子に送信することに依存する必要があります。
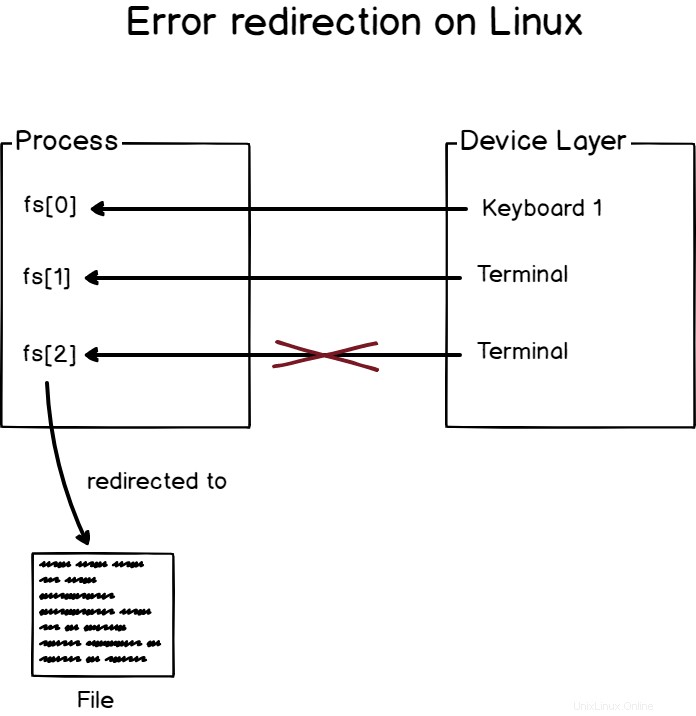
Linuxでエラー出力をリダイレクトするには、「 2>」を使用します ”演算子
$ command 2> file端末でエラーメッセージを生成するために、pingコマンドの例を使用してみましょう。

次に、エラー出力がエラーファイルにリダイレクトされるバージョンを見てみましょう。

ご覧のとおり、「2>」演算子を使用してエラーを「error-file」ファイルにリダイレクトしました。
標準出力のみをファイルにリダイレクトすると、何も出力されません。

ご覧のとおり、エラーメッセージが端末に出力され、「通常のファイル」の出力には何も追加されませんでした。
b –標準エラーと標準出力の組み合わせ
場合によっては、エラーメッセージを標準出力と組み合わせてファイルにリダイレクトしたい場合があります。
一部のプログラムは標準メッセージまたはエラーメッセージを返すだけでなく、2つを組み合わせて返すため、特に便利です。
検索の例を見てみましょう 指図。
sudo権限なしでルートディレクトリでfindコマンドを実行している場合、たとえば自分が所有していないプロセスなど、一部のディレクトリへのアクセスが許可されていない可能性があります。
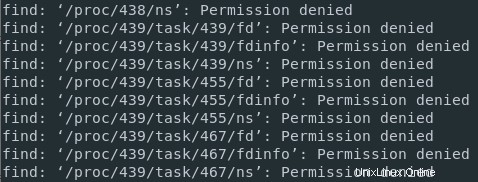
結果として、標準メッセージが混在することになります (私のユーザーが所有するファイル)およびエラーメッセージ (私が所有していないディレクトリにアクセスしようとしたとき)
この場合、両方の出力をファイルに保存したいと思います。
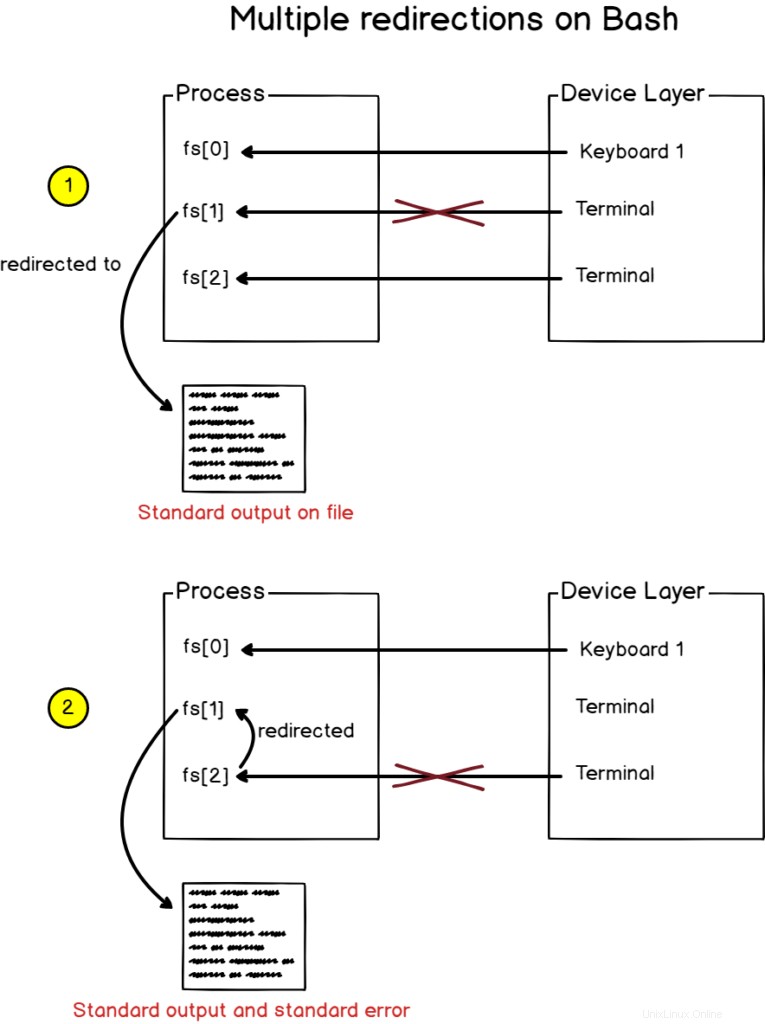
標準出力とエラー出力をファイルにリダイレクトするには、「>」の前に「2 <&1」構文を使用します。
$ find / -user devconnected > file 2>&1または、「&>」を使用することもできます 出力とエラーの両方をリダイレクトするためのより短い方法としての構文。
$ find / -user devconnected &> fileでは、ここで何が起こったのでしょうか?
bashは複数のリダイレクトを検出すると、それらを左から右に処理します。
結果として、find関数の出力は最初にファイルにリダイレクトされます。
次に、2番目のリダイレクトが処理され、標準エラーが標準出力(以前にファイルに割り当てられていたもの)にリダイレクトされます。
5 – Linuxのパイプラインとは何ですか?
パイプラインはリダイレクトとは少し異なります。
標準の入力または出力のリダイレクトを行う場合、基本的にデフォルトの入力または出力をカスタムファイルに上書きしていました。
パイプラインを使用すると、入力または出力を上書きすることはありませんが、それらを相互に接続することになります。
Linuxシステムでは、パイプラインを使用してプロセスを相互に接続し、あるプログラムからの標準出力を別のプログラムの標準入力にリンクします。
複数のプロセスをパイプラインでリンクできます (またはパイプ )
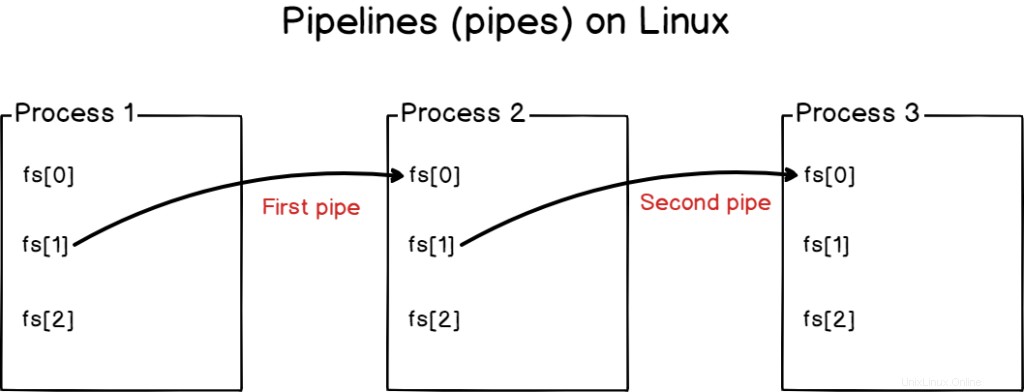
パイプは、複雑なクエリを作成するためにシステム管理者によって頻繁に使用されます 単純なクエリを組み合わせることによって。
最も一般的な例の1つは、ファイルのコンテンツにカスタムフィルタを適用した後、テキストファイルの行数を数えることです。
前のセクションで作成したドメインファイルに戻り、国の拡張子を変更して.netドメインを含めましょう。
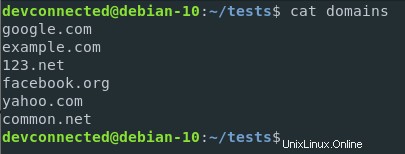
ここで、ファイル内の.comドメインの数をカウントするとします。
どのようにそれを実行しますか? パイプを使用する。
まず、結果をフィルタリングして、ファイル内の.comドメインのみを分離します。次に、結果を「wc」コマンドにパイプしてカウントします。
ファイル内の.comドメインをカウントする方法は次のとおりです。
$ grep .com domains | wc -l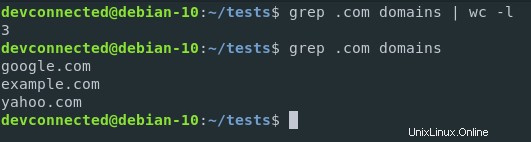
それでも理解できない場合に備えて、図で何が起こったかを次に示します。
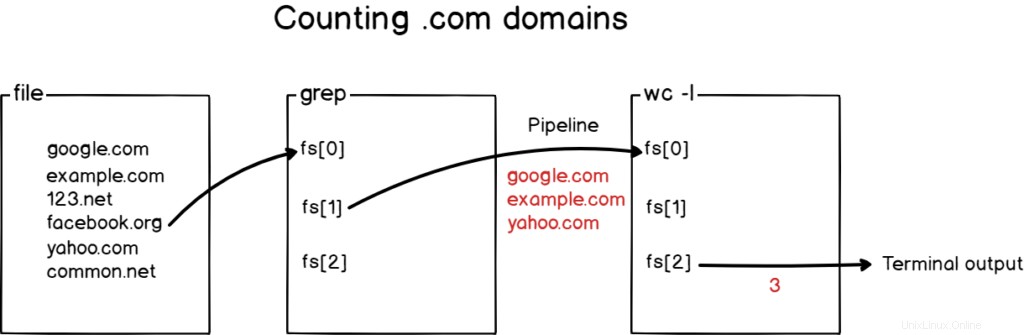
素晴らしい!
6 –結論
今日のチュートリアルでは、入力と出力のリダイレクトとは何か、Linuxシステムで管理操作を実行するためにそれを効果的に使用する方法を学びました。
パイプライン(またはパイプ)についても学びました これは、ホスト上でより長く複雑なコマンドを実行するためにコマンドを連鎖させるために使用されます。
Linuxの管理に興味がある場合は、devconnectedに専用のカテゴリがありますので、ぜひチェックしてください!