私がネットワークに焦点を当てた役割で働いていたとき、最大の課題の1つは、常にネットワークとシステムエンジニアリングの間のギャップを埋めることでした。システム管理者は、ネットワークの可視性が不足しているため、ネットワークの停止や奇妙な問題を非難することがよくあります。ネットワーク管理者は、サーバーを制御できず、ネットワークに対する「無実であることが証明されるまで有罪」の態度に疲れて、ネットワークエンドポイントを非難することがよくありました。
もちろん、非難は問題を解決しません。時間をかけて誰かのドメインの基本を理解することは、他のチームとの関係を改善し、問題のより迅速な解決策を導き出すのに大いに役立ちます。この事実は、システム管理者に特に当てはまります。ネットワークのトラブルシューティングの基本を理解することで、ネットワークに障害があると思われる場合に、ネットワークの同僚に強力な証拠を提供できます。同様に、多くの場合、最初のトラブルシューティングを自分で実行することで時間を節約できます。
この記事では、Linuxコマンドラインを介したネットワークトラブルシューティングの基本について説明します。
TCP/IPモデルの簡単なレビュー
まず、TCP/IPネットワークモデルの基本を確認してみましょう。ほとんどの人がオープンシステム相互接続(OSI)モデルを使用してネットワーク理論について議論していますが、TCP / IPモデルは、最新のネットワークに導入されている一連のプロトコルをより正確に表しています。
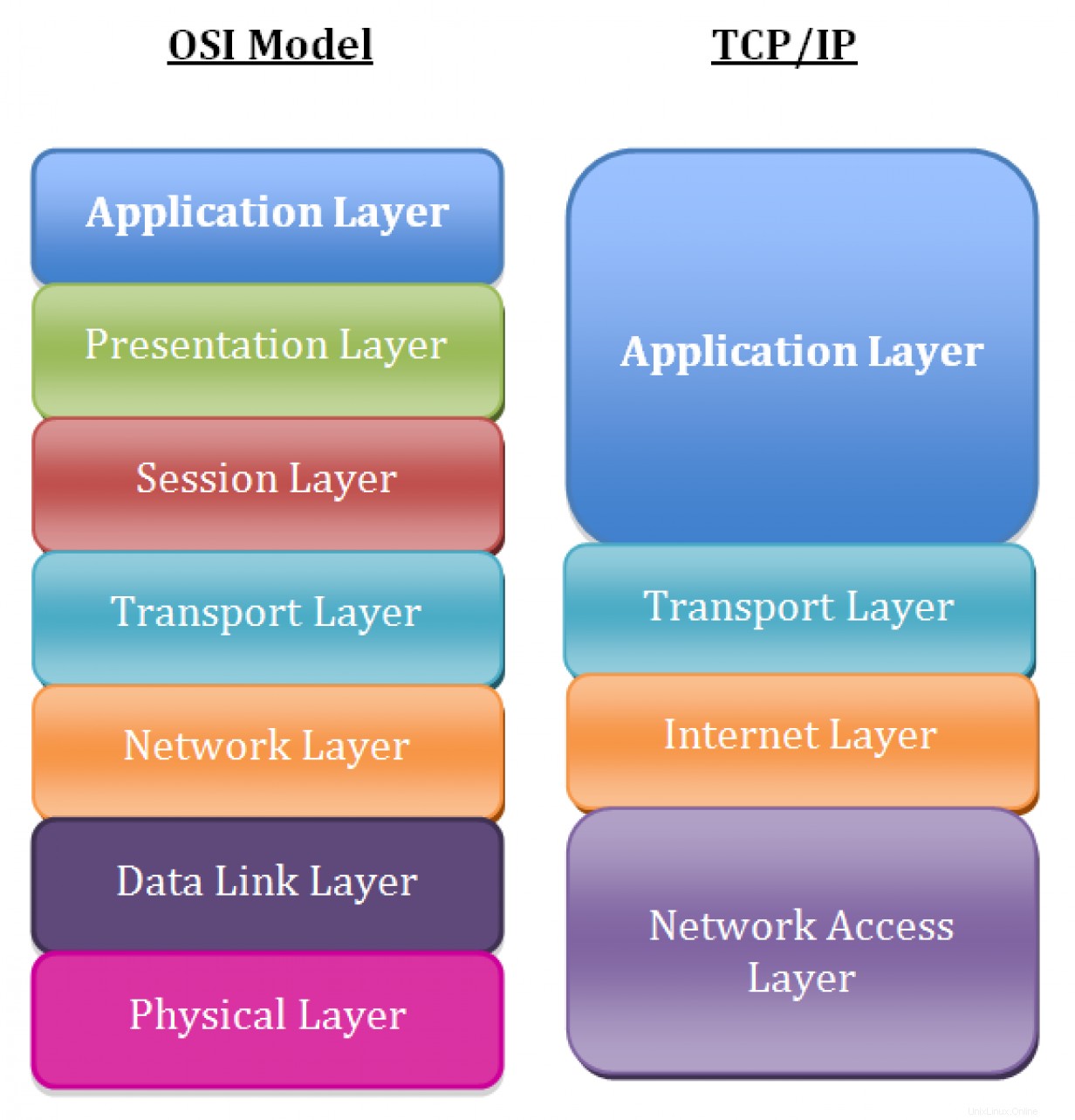
TCP / IPネットワークモデルのレイヤーには、順番に次のものが含まれます。
- レイヤー5: アプリケーション
- レイヤー4: 輸送
- レイヤー3: ネットワーク/インターネット
- レイヤー2: データリンク
- レイヤー1: 物理的
このモデルに精通していることを前提とし、スタックレイヤー1から4で問題をトラブルシューティングする方法について説明します。トラブルシューティングを開始する場所は状況によって異なります。たとえば、サーバーにSSHで接続できるが、サーバーがMySQLデータベースに接続できない場合、問題はローカルサーバーの物理層またはデータリンク層にあるとは考えられません。一般に、スタックを下に向かって作業することをお勧めします。アプリケーションから始めて、問題を特定するまで、各下位層のトラブルシューティングを徐々に行います。
その背景がわからなくなったら、コマンドラインにジャンプしてトラブルシューティングを始めましょう。
レイヤー1:物理レイヤー
多くの場合、物理層は当然のことと見なされますが(「ケーブルが接続されていることを確認しましたか?」)、Linuxコマンドラインから物理層の問題を簡単にトラブルシューティングできます。これは、ホストへのコンソール接続がある場合ですが、一部のリモートシステムには当てはまらない場合があります。
最も基本的な質問から始めましょう:私たちの物理的なインターフェースはアップしていますか? ip link show コマンドは私たちに教えてくれます:
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
eth0インターフェイスの上記の出力にDOWNが表示されていることに注意してください。この結果は、レイヤー1が表示されないことを意味します。ケーブルまたは接続のリモートエンド(スイッチなど)に問題がないかどうかを確認して、トラブルシューティングを試みる場合があります。
ただし、ケーブルのチェックを開始する前に、インターフェイスが無効になっているだけではないことを確認することをお勧めします。インターフェイスを起動するコマンドを発行すると、この問題を除外できます。
# ip link set eth0 up
ip link showの出力 一目で解析するのは難しい場合があります。幸い、-br switchは、この出力をはるかに読みやすい表形式で出力します。
# ip -br link show
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>
eth0 UP 52:54:00:82:d6:6e <BROADCAST,MULTICAST,UP,LOWER_UP>
ip link set eth0 upのようです トリックを行い、eth0が復活しました。
これらのコマンドは、明らかな物理的な問題のトラブルシューティングに最適ですが、より陰湿な問題についてはどうでしょうか。インターフェイスが誤った速度でネゴシエートする可能性があります。または、衝突や物理層の問題により、パケット損失や破損が発生し、コストのかかる再送信が発生する可能性があります。これらの問題のトラブルシューティングを開始するにはどうすればよいですか?
-sを使用できます ipでフラグを立てる インターフェイスに関する追加の統計情報を出力するコマンド。以下の出力は、ほとんどクリーンなインターフェースを示しており、ドロップされた受信パケットはわずかであり、物理層の問題の他の兆候はありません。
# ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
34107919 5808 0 6 0 0
TX: bytes packets errors dropped carrier collsns
434573 4487 0 0 0 0
より高度なレイヤー1のトラブルシューティングについては、ethtool ユーティリティは優れたオプションです。このコマンドの特に適切な使用例は、インターフェイスが正しい速度をネゴシエートしたかどうかを確認することです。間違った速度をネゴシエートしたインターフェイス(たとえば、1Gbpsの速度のみを報告する10Gbpsインターフェイス)は、ハードウェア/ケーブルの問題、またはリンクの片側でのネゴシエーションの設定ミス(スイッチポートの設定ミスなど)を示している可能性があります。
結果は次のようになります:
# ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
MDI-X: on (auto)
Supports Wake-on: d
Wake-on: d
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
上記の出力は、1000Mbpsの速度と全二重に正しくネゴシエートされたリンクを示していることに注意してください。
レイヤー2:データリンクレイヤー
データリンク層はローカルを担当します ネットワーク接続;基本的に、同じレイヤー2ドメイン(一般にローカルエリアネットワークと呼ばれます)上のホスト間のフレームの通信。ほとんどのsysadminに最も関連するレイヤー2プロトコルは、アドレス解決プロトコル(ARP)です。これは、レイヤー3IPアドレスをレイヤー2イーサネットMACアドレスにマップします。ホストがローカルネットワーク上の別のホスト(デフォルトゲートウェイなど)に接続しようとすると、他のホストのIPアドレスを持っている可能性がありますが、他のホストのMACアドレスを認識していません。 ARPはこの問題を解決し、MACアドレスを特定します。
発生する可能性のある一般的な問題は、特にホストのデフォルトゲートウェイの場合に入力されないARPエントリです。ローカルホストがゲートウェイのレイヤー2MACアドレスを正常に解決できない場合、ローカルホストはリモートネットワークにトラフィックを送信できません。この問題は、ゲートウェイに間違ったIPアドレスが構成されていることが原因であるか、スイッチポートの構成が間違っているなどの別の問題である可能性があります。
ip neighborを使用してARPテーブルのエントリを確認できます コマンド:
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
ゲートウェイのMACアドレスが入力されていることに注意してください(ゲートウェイを見つける方法については、次のセクションで詳しく説明します)。 ARPに問題があった場合、解決に失敗します:
# ip neighbor show
192.168.122.1 dev eth0 FAILED
ip neighborのもう1つの一般的な使用法 コマンドには、ARPテーブルの操作が含まれます。ネットワークチームがアップストリームルーター(サーバーのデフォルトゲートウェイ)を交換したところを想像してみてください。 MACアドレスは工場で割り当てられたハードウェアアドレスであるため、MACアドレスも変更されている可能性があります。
注: 工場でデバイスに一意のMACアドレスが割り当てられていますが、これらを変更またはスプーフィングすることができます。最近のネットワークの多くは、生成されたMACアドレスを使用する仮想ルーター冗長プロトコル(VRRP)などのプロトコルも使用することがよくあります。
Linuxは一定期間ARPエントリをキャッシュするため、ゲートウェイのARPエントリがタイムアウトするまで、デフォルトゲートウェイにトラフィックを送信できない場合があります。非常に重要なシステムの場合、この結果は望ましくありません。幸い、ARPエントリを手動で削除すると、新しいARP検出プロセスが強制されます。
# ip neighbor show
192.168.122.170 dev eth0 lladdr 52:54:00:04:2c:5d REACHABLE
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
# ip neighbor delete 192.168.122.170 dev eth0
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
上記の例では、eth0に192.168.122.70のARPエントリが入力されています。次に、ARPエントリを削除すると、テーブルから削除されたことがわかります。
レイヤー3:ネットワーク/インターネットレイヤー
レイヤー3には、すべてのシステム管理者に馴染みのあるIPアドレスの操作が含まれます。 IPアドレッシングは、ローカルネットワークの外部にある他のホストに到達する方法をホストに提供します(ただし、ローカルネットワークでも頻繁に使用します)。トラブルシューティングの最初のステップの1つは、マシンのローカルIPアドレスを確認することです。これは、ip addressを使用して実行できます。 コマンド、ここでも-brを使用します 出力を簡略化するフラグ:
# ip -br address show
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.135/24 fe80::184e:a34d:1d37:441a/64 fe80::c52f:d96e:a4a2:743/64
eth0インターフェースのIPv4アドレスが192.168.122.135であることがわかります。 IPアドレスがない場合は、その問題のトラブルシューティングを行います。 IPアドレスが不足しているのは、ネットワークインターフェイスの設定ファイルが正しくないなど、ローカルの設定ミスが原因であるか、DHCPの問題が原因である可能性があります。
ほとんどのシステム管理者がレイヤー3のトラブルシューティングに使用する最も一般的な最前線のツールは、pingです。 効用。 PingはICMPエコー要求パケットをリモートホストに送信し、ICMPエコー応答を返します。リモートホストへの接続に問題がある場合は、ping トラブルシューティングを開始するための一般的なユーティリティです。コマンドラインから単純なpingを実行すると、ICMPエコーがリモートホストに無期限に送信されます。 pingを終了するか、-c <num pings>を渡すには、CTRL+Cを押す必要があります フラグ、そのように:
# ping www.google.com
PING www.google.com (172.217.165.4) 56(84) bytes of data.
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=1 ttl=54 time=12.5 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=2 ttl=54 time=12.6 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=3 ttl=54 time=12.5 ms
^C
--- www.google.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 12.527/12.567/12.615/0.036 ms
各pingには、応答の受信にかかった時間が含まれていることに注意してください。 ping中 ホストが生きていて応答しているかどうかを簡単に見分けることができますが、それは決して決定的なものではありません。多くのネットワーク事業者は、セキュリティ対策としてICMPパケットをブロックしていますが、他の多くの事業者はこの方法に同意していません。もう1つの一般的な落とし穴は、ネットワーク遅延の正確な指標として時間フィールドに依存することです。 ICMPパケットは、中間ネットワークギアによってレート制限される可能性があるため、アプリケーションの遅延を正確に表すために信頼するべきではありません。
レイヤ3トラブルシューティングツールベルトの次のツールは、tracerouteです。 指図。 Tracerouteは、IPパケットのTime to Live(TTL)フィールドを利用して、トラフィックが宛先に到達するまでのパスを決定します。 Tracerouteは、TTLが1の場合から、一度に1つのパケットを送信します。パケットは転送中に期限切れになるため、アップストリームルータはICMPTime-to-LiveExceededパケットを送り返します。次に、TracerouteはTTLをインクリメントして、ネクストホップを決定します。結果の出力は、パケットが宛先に向かう途中で通過した中間ルーターのリストです。
# traceroute www.google.com
traceroute to www.google.com (172.217.10.36), 30 hops max, 60 byte packets
1 acritelli-laptop (192.168.122.1) 0.103 ms 0.057 ms 0.027 ms
2 192.168.1.1 (192.168.1.1) 5.302 ms 8.024 ms 8.021 ms
3 142.254.218.133 (142.254.218.133) 20.754 ms 25.862 ms 25.826 ms
4 agg58.rochnyei01h.northeast.rr.com (24.58.233.117) 35.770 ms 35.772 ms 35.754 ms
5 agg62.hnrtnyaf02r.northeast.rr.com (24.58.52.46) 25.983 ms 32.833 ms 32.864 ms
6 be28.albynyyf01r.northeast.rr.com (24.58.32.70) 43.963 ms 43.067 ms 43.084 ms
7 bu-ether16.nycmny837aw-bcr00.tbone.rr.com (66.109.6.74) 47.566 ms 32.169 ms 32.995 ms
8 0.ae1.pr0.nyc20.tbone.rr.com (66.109.6.163) 27.277 ms * 0.ae4.pr0.nyc20.tbone.rr.com (66.109.1.35) 32.270 ms
9 ix-ae-6-0.tcore1.n75-new-york.as6453.net (66.110.96.53) 32.224 ms ix-ae-10-0.tcore1.n75-new-york.as6453.net (66.110.96.13) 36.775 ms 36.701 ms
10 72.14.195.232 (72.14.195.232) 32.041 ms 31.935 ms 31.843 ms
11 * * *
12 216.239.62.20 (216.239.62.20) 70.011 ms 172.253.69.220 (172.253.69.220) 83.370 ms lga34s13-in-f4.1e100.net (172.217.10.36) 38.067 ms
Tracerouteは優れたツールのように見えますが、その制限を理解することが重要です。 ICMPと同様に、中間ルーターはtracerouteのパケットをフィルタリングできます。 ICMPTime-to-LiveExceededメッセージなどに依存します。ただし、さらに重要なのは、トラフィックが宛先との間でたどるパスが必ずしも対称であるとは限らず、常に同じであるとは限らないことです。 Tracerouteは、トラフィックが目的地との間で直線的な経路をたどっていると誤解させる可能性があります。ただし、このような状況になることはめったにありません。トラフィックは異なるリターンパスをたどる可能性があり、パスはさまざまな理由で動的に変化する可能性があります。 traceroute 小規模な企業ネットワークで正確なパス表現を提供する場合がありますが、大規模なネットワークやインターネットでトレースしようとすると正確でないことがよくあります。
発生する可能性が高いもう1つの一般的な問題は、特定のルートのアップストリームゲートウェイの欠如、またはデフォルトルートの欠如です。 IPパケットが別のネットワークに送信される場合、さらに処理するためにゲートウェイに送信する必要があります。ゲートウェイは、パケットを最終的な宛先にルーティングする方法を知っている必要があります。さまざまなルートのゲートウェイのリストは、ルーティングテーブルに保存されます。 、ip routeを使用して検査および操作できます コマンド。
ip route showを使用してルーティングテーブルを印刷できます コマンド:
# ip route show
default via 192.168.122.1 dev eth0 proto dhcp metric 100
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.135 metric 100
単純なトポロジでは、多くの場合、テーブルの上部にある「デフォルト」エントリで表されるデフォルトゲートウェイが構成されています。デフォルトゲートウェイがないか正しくないことが一般的な問題です。
トポロジがより複雑で、ネットワークごとに異なるルートが必要な場合は、ルートで特定のプレフィックスを確認できます。
# ip route show 10.0.0.0/8
10.0.0.0/8 via 192.168.122.200 dev eth0
上記の例では、10.0.0.0 / 8ネットワーク宛てのすべてのトラフィックを別のゲートウェイ(192.168.122.200)に送信しています。
レイヤ3プロトコルではありませんが、IPアドレッシングについて話しているときにDNSについて言及する価値があります。特に、ドメインネームシステム(DNS)は、IPアドレスをwww.redhat.comなどの人間が読める形式の名前に変換します。 。 DNSの問題は非常に一般的であり、トラブルシューティングが不透明な場合があります。 DNSについてはたくさんの本やオンラインガイドが書かれていますが、ここでは基本に焦点を当てます。
DNSの問題の明らかな兆候は、IPアドレスでリモートホストに接続できることですが、ホスト名では接続できません。クイックnslookupの実行 ホスト名でかなりのことを教えてくれます(nslookup bind-utilsの一部です Red Hat Enterprise Linuxベースのシステムのパッケージ):
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.3.100
上記の出力は、192.168.122.1に対してルックアップが実行され、結果のIPアドレスが172.217.3.100であったサーバーを示しています。
nslookupを実行する場合 ホストの場合、ただしping またはtraceroute 別のIPアドレスを使用してみてください。おそらく、ホストファイルエントリの問題が発生しています。その結果、ホストファイルに問題がないか調べます。
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.12.132
# ping -c 1 www.google.com
PING www.google.com (1.2.3.4) 56(84) bytes of data.
^C
--- www.google.com ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
1.2.3.4 www.google.com
上記の例では、www.google.comのアドレスに注意してください。 172.217.12.132に解決されました。ただし、ホストにpingを実行しようとすると、トラフィックは1.2.3.4に送信されていました。 /etc/hostsを見てください ファイル、誰かが不注意に追加したに違いないオーバーライドを見ることができます。ホストファイルのオーバーライドの問題は非常に 特に、開発中にコードをテストするためにこれらのオーバーライドを頻繁に行う必要があるアプリケーション開発者と協力している場合は一般的です。
レイヤー4:トランスポート層
トランスポート層はTCPプロトコルとUDPプロトコルで構成され、TCPはコネクション型プロトコルであり、UDPはコネクションレス型です。アプリケーションはソケットでリッスンします 、IPアドレスとポートで構成されます。特定のポートのIPアドレス宛てのトラフィックは、カーネルによってリスニングアプリケーションに転送されます。これらのプロトコルの完全な説明はこの記事の範囲を超えているため、これらのレイヤーでの接続の問題をトラブルシューティングする方法に焦点を当てます。
最初に実行したいことは、ローカルホストでリッスンしているポートを確認することです。この結果は、WebサーバーやSSHサーバーなど、マシン上の特定のサービスに接続できない場合に役立ちます。もう1つの一般的な問題は、ポートで他の何かがリッスンしているためにデーモンまたはサービスが起動しない場合に発生します。 ss コマンドは、これらのタイプのアクションを実行するために非常に貴重です:
# ss -tunlp4
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:68 *:* users:(("dhclient",pid=3167,fd=6))
udp UNCONN 0 0 127.0.0.1:323 *:* users:(("chronyd",pid=2821,fd=1))
tcp LISTEN 0 128 *:22 *:* users:(("sshd",pid=3366,fd=3))
tcp LISTEN 0 100 127.0.0.1:25 *:* users:(("master",pid=3600,fd=13))
これらのフラグを分解してみましょう:
- -t -TCPポートを表示します。
- -u -UDPポートを表示します。
- -n -ホスト名を解決しようとしないでください。
- -l </ strong> -リスニングポートのみを表示します。
- -p -特定のソケットを使用しているプロセスを表示します。
- -4 -IPv4ソケットのみを表示します。
出力を見ると、いくつかのリスニングサービスを見ることができます。 sshd アプリケーションは、*:22で示されるすべてのIPアドレスのポート22でリッスンしています。 出力。
ss コマンドは強力なツールであり、その簡単なマニュアルページを確認すると、フラグやオプションを見つけて、探しているものを見つけるのに役立ちます。
もう1つの一般的なトラブルシューティングのシナリオには、リモート接続が含まれます。ローカルマシンがポート3306のMySQLなどのリモートポートに接続できないと想像してください。これらのタイプの問題のトラブルシューティングを行う場合、ありそうもないが一般的にインストールされているツールが友だちになる可能性があります。telnet 。 telnet コマンドは、指定したホストおよびポートとのTCP接続を確立しようとします。この機能は、リモートTCP接続のテストに最適です:
# telnet database.example.com 3306
Trying 192.168.1.10...
^C
上記の出力では、telnet 私たちがそれを殺すまでハングします。この結果は、リモートマシンのポート3306にアクセスできないことを示しています。アプリケーションがリッスンしていない可能性があり、ssを使用して前のトラブルシューティング手順を使用する必要があります リモートホスト上—アクセスできる場合。もう1つの可能性は、トラフィックをフィルタリングしているホストまたは中間ファイアウォールです。ネットワークチームと協力して、パス全体のレイヤー4接続を確認する必要がある場合があります。
TelnetはTCPで正常に機能しますが、UDPについてはどうでしょうか。 netcat ツールは、リモートUDPポートをチェックする簡単な方法を提供します:
# nc 192.168.122.1 -u 80
test
Ncat: Connection refused.
netcat ユーティリティは、TCP接続のテストなど、他の多くの目的に使用できます。 netcatに注意してください システムにインストールされていない可能性があり、放置しておくことはセキュリティリスクと見なされることがよくあります。トラブルシューティングが完了したら、アンインストールを検討することをお勧めします。
上記の例では、一般的な単純なユーティリティについて説明しました。ただし、はるかに強力なツールはnmapです。 。本全体がnmapに捧げられています 機能性があるため、この初心者向けの記事では取り上げませんが、それが実行できることのいくつかを知っておく必要があります。
- リモートマシンをスキャンするTCPおよびUDPポート。
- OSフィンガープリンティング。
- リモートポートが閉じているか、単にフィルタリングされているかを判断します。
この記事では、ケーブルやスイッチからIPアドレスやポートに至るまで、ネットワークスタックを上っていく過程で、多くの入門的なネットワークグラウンドについて説明しました。ここで説明するツールは、基本的なネットワーク接続の問題をトラブルシューティングするための良い出発点となるはずであり、ネットワークチームに可能な限り詳細を提供しようとするときに役立つはずです。
ネットワークのトラブルシューティングの過程で進むにつれて、間違いなく、これまで知られていなかったコマンドフラグ、派手なワンライナー、強力な新しいツール(tcpdump)に出くわします。 とWiresharkが私のお気に入りです)ネットワークの問題の原因を掘り下げます。楽しんでください、そして覚えておいてください:パケットは嘘をつきません!