はじめに
phoenixNAPベアメタルクラウドは、開発者がベアメタルサーバーの作成を自動化できるようにするRESTfulAPIインターフェースを公開します。
システムの機能を示すために、この記事では、BMCAPIを活用してベアメタルクラウドでのSparkクラスターのプロビジョニングを自動化する方法に関するPythonコード例を説明および提供します。 。

前提条件
- phoenixNAPベアメタルクラウドアカウント
- OAuthアクセストークン
Sparkクラスターのデプロイを自動化する方法
以下の手順は、phoenixNAPのベアメタルクラウド環境に適用されます。この記事にあるPythonコード例は、他の環境では機能しない可能性があります。
Apache Sparkクラスターをデプロイしてアクセスするために必要な手順:
1.アクセストークンを生成します。
2.UbuntuOSを実行するベアメタルクラウドサーバーを作成します。
3.作成したサーバーインスタンスにApacheSparkクラスターをデプロイします。
4.生成されたリンクをたどってApacheSparkダッシュボードにアクセスします。
この記事では、ベアメタルクラウドAPIとシェルコマンドを活用して上記の手順を完了するPythonコードセグメントのサブセットに焦点を当てています。
ステップ1:アクセストークンを取得する
BMC APIにリクエストを送信する前に、 client_idを使用してOAuthアクセストークンを取得する必要があります およびclient_secret BMCポータルに登録されています。
client_idとclient_secretに登録する方法の詳細については、Bare MetalCloudAPIクイックスタートガイドを参照してください。
以下は、APIのアクセストークンを生成するPython関数です。
def get_access_token(client_id: str, client_secret: str) -> str:
"""Retrieves an access token from BMC auth by using the client ID and the
client Secret."""
credentials = "%s:%s" % (client_id, client_secret)
basic_auth = standard_b64encode(credentials.encode("utf-8"))
response = requests.post(' https://api.phoenixnap.com/bmc/v0/servers',
headers={
'Content-Type': 'application/x-www-form-urlencoded',
'Authorization': 'Basic %s' % basic_auth.decode("utf-8")},
data={'grant_type': 'client_credentials'})
if response.status_code != 200:
raise Exception('Error: {}. {}'.format(response.status_code, response.json()))
return response.json()['access_token']
ステップ2:ベアメタルサーバーインスタンスを作成する
POST/サーバーのRESTAPI呼び出しを使用して、ベアメタルサーバーインスタンスを作成します。 POST /サーバーリクエストごとに、データセンターの場所、サーバーの種類、OSなどの必要なパラメータを指定します。
以下は、ベアメタルサーバーを作成するためにBMCAPIを呼び出すPython関数です。
def __do_create_server(session, server):
response = session.post('https://api.phoenixnap.com/bmc/v0/servers'),
data=json.dumps(server))
if response.status_code != 200:
print("Error creating server: {}".format(json.dumps(response.json())))
else:
print("{}".format(json.dumps(response.json())))
return response.json()
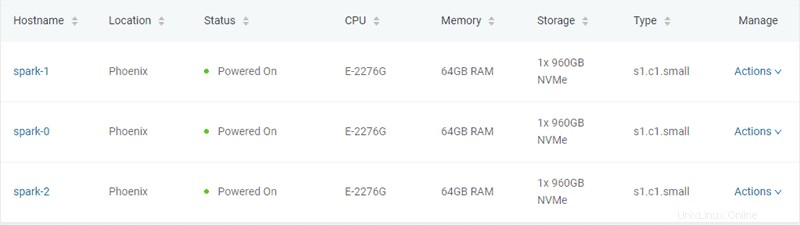
この例では、server-settings.confファイルで指定されているように、タイプ「s1.c1.small」の3つのベアメタルサーバーが作成されます。
{
"ssh-key" : "ssh-rsa xxxxxx== username",
"servers_quantity" : 3,
"type" : "s1.c1.small",
"hostname" : "spark",
"description" : "spark",
"public" : True,
"location" : "PHX",
"os" : "ubuntu/bionic"
}
トークンを生成してサーバーをプロビジョニングするPythonスクリプトから期待される出力は、次のとおりです。
Retrieving token
Successfully retrieved API token
Creating servers...
{
"id": "5ee9c1b84a9ca71ea6b9b766",
"status": "creating",
"hostname": "spark-1",
"description": "spark-1",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.11"
],
"publicIpAddresses": [
"131.153.143.250",
"131.153.143.251",
"131.153.143.252",
"131.153.143.253",
"131.153.143.254"
]
}
Server created, provisioning spark-1...
{
"id": "5ee9c1b84a9ca71ea6b9b767",
"status": "creating",
"hostname": "spark-0",
"description": "spark-0",
"os": "ubuntu/bionic",
"type": "s1.c1.small",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.12"
],
"publicIpAddresses": [
"131.153.143.50",
"131.153.143.51",
"131.153.143.52",
"131.153.143.53",
"131.153.143.54"
]
}
Server created, provisioning spark-0...
{
"id": "5ee9c1b84a9ca71ea6b9b768",
"status": "creating",
"hostname": "spark-2",
"description": "spark-2",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.13"
],
"publicIpAddresses": [
"131.153.142.234",
"131.153.142.235",
"131.153.142.236",
"131.153.142.237",
"131.153.142.238"
]
}
Server created, provisioning spark-2...
Waiting for servers to be provisioned... 3つのベアメタルサーバーを作成すると、スクリプトはBMC APIと通信して、プロビジョニングが完了し、サーバーの電源がオンになるまでサーバーのステータスを確認します。
ステップ3:ApacheSparkクラスターをプロビジョニングする
サーバーがプロビジョニングされると、PythonスクリプトはサーバーのパブリックIPアドレスを使用してSSH接続を確立します。次に、スクリプトはUbuntuサーバーにSparkをインストールします。これには、 JDKのインストールが含まれます 、 Scala 、 Git およびスパーク すべてのサーバーで。
プロセスを開始するには、 all_hosts.shを実行します すべてのサーバー上のファイル。このスクリプトは、ダウンロードとインストールの手順、およびクラスターを使用できるように準備するために必要な環境構成を提供します。
Apache Sparkには、サーバーをマスターノードおよびワーカーノードとして構成するスクリプトが含まれています。ワーカーノードを構成する際の唯一の制約は、マスターノードがすでに構成されていることです。プロビジョニングされる最初のサーバーは、Sparkマスターノードとして割り当てられます。
次のPython関数がそのタスクを実行します:
def wait_server_ready(function_scheduler, server_data):
json_server = bmc_api.get_server(REQUEST, server_data['id'])
if json_server['status'] == "creating":
main_scheduler.enter(2, 1, wait_server_ready, (function_scheduler, server_data))
elif json_server['status'] == "powered-on" and not data['has_a_master_server']:
server_data['status'] = json_server['status']
server_data['master'] = True
server_data['joined'] = True
data['has_a_master_server'] = True
data['master_ip'] = json_server['publicIpAddresses'][0]
data['master_hostname'] = json_server['hostname']
print("ASSIGNED MASTER SERVER: {}".format(data['master_hostname']))master_host.shを実行します 最初のサーバーをマスターノードとして構成するファイル。以下のmaster_host.shのコンテンツを参照してください ファイル:
#!/bin/bash
echo "Setting up master node"
/opt/spark/sbin/start-master.shマスターノードが割り当てられて構成されると、他の2つのノードがSparkクラスターに追加されます。
以下のworker_host.shのコンテンツを参照してください ファイル:
#!/bin/bash
echo "Setting up master node on /etc/hosts"
echo "$1 $2 $2" | sudo tee -a /etc/hosts
echo "Starting worker node"
echo "Joining worker node to the cluster"
/opt/spark/sbin/start-slave.sh spark://$2:7077
ApacheSparkクラスターのプロビジョニングが完了しました。以下は、Pythonスクリプトから期待される出力です。
ASSIGNED MASTER SERVER: spark-2
Running all_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running master_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up master node
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.master.Master-1-spark-2.out
Master host installed
Running all_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running all_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running slave_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-0.out
Running slave_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-1.out
Setup servers done
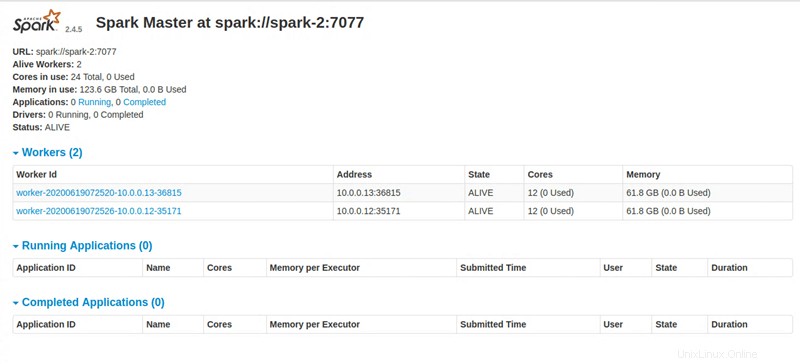
Master node UI: http://131.153.142.234:8080
ステップ4:ApacheSparkダッシュボードにアクセスする
すべての命令を実行すると、PythonスクリプトはApacheSparkダッシュボードにアクセスするためのリンクを提供します。