はじめに
Pandasは、主にデータ分析に使用されるオープンソースのPythonライブラリです。 Pandasパッケージのツールのコレクションは、Pythonでデータを準備、変換、および集約するための重要なリソースです。
PandasライブラリはNumPyパッケージに基づいており、さまざまな既存のモジュールと互換性があります。 2つの新しい表形式のデータ構造の追加シリーズ およびデータフレーム 、ユーザーがリレーショナルデータベースやスプレッドシートと同様の機能を利用できるようにします。
この記事では、PythonPandasのインストール方法について説明します。 基本的なパンダコマンドを紹介します。

Pythonパンダをインストールする方法
Pythonの人気により、多数のディストリビューションとパッケージが作成されました。パッケージマネージャーは、インストールプロセスの自動化、アップグレードの管理、Pythonパッケージと依存関係の構成、削除に使用される効率的なツールです。
注: Pythonバージョン3.6.1 以上がPandasインストールの前提条件です。詳細なガイドを使用して、現在のPythonバージョンを確認してください。必要なPythonバージョンがない場合は、次の詳細ガイドのいずれかを使用できます。
- Ubuntu18.04またはUbuntu20.04にPython3.8をインストールする方法。
- Windows10にPython3をインストールする方法
- 最新バージョンのPython3をCentos7にインストールする方法
AnacondaでPandasをインストールする
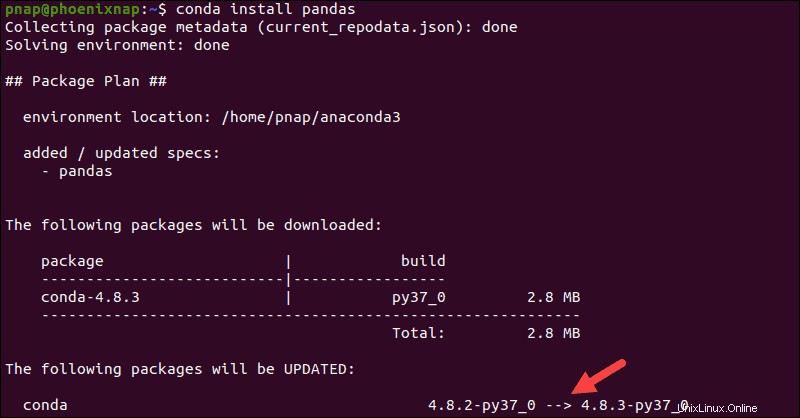
Anacondaパッケージには、すでにPandasライブラリが含まれています。ターミナルで次のコマンドを入力して、現在のPandasのバージョンを確認します。
conda list pandas出力はパンダのバージョンとビルドを確認します。

Pandasがシステムに存在しない場合は、 condaを使用することもできます パンダをインストールするためのツール:
conda install pandasAnacondaは、モジュールと依存関係のコレクションをインストールすることにより、トランザクション全体を管理します。
pipを使用してPandasをインストールする
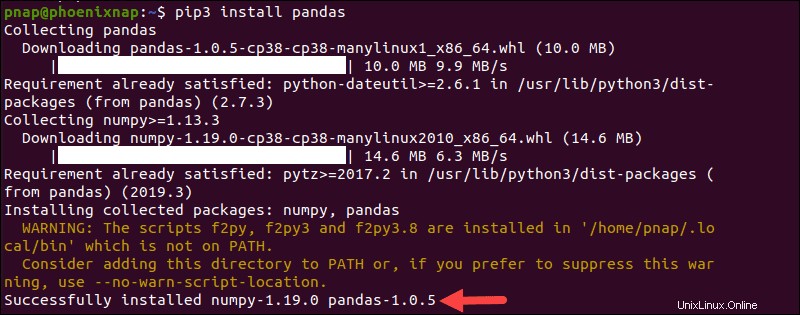
PyPIソフトウェアリポジトリは定期的に管理され、Pythonベースのソフトウェアの最新バージョンを維持しています。 PyPIパッケージマネージャーであるpipをインストールし、それを使用してPythonパンダをデプロイします。
pip3 install pandasダウンロードとインストールのプロセスは、完了するまでに少し時間がかかります。
LinuxにPandasをインストールする
あらかじめパッケージ化されたソリューションをインストールすることが、常に推奨されるオプションであるとは限りません。他のモジュールと同じ方法を使用して、任意のLinuxディストリビューションにPandasをインストールできます。たとえば、次のコマンドを使用して、Ubuntu20.04に基本的なPandasモジュールをインストールします。
sudo apt install python3-pandas -y Linuxリポジトリのパッケージには、利用可能な最新バージョンが含まれていない場合が多いことに注意してください。
Pythonパンダの使用
Pythonの柔軟性により、さまざまなフレームワークでPandasを使用できます。これには、基本的なPythonコードエディター、端末のPythonシェルから発行されるコマンド、Spyder、PyCharm、Atomなどのインタラクティブな環境が含まれます。このチュートリアルの実際の例とコマンドは、JupyterNotebookを使用して提示されています。
PythonPandasライブラリのインポート
データを分析して処理するには、Python環境にPandasライブラリをインポートする必要があります。 Pythonセッションを開始し、次のコマンドを使用してPandasをインポートします。
import pandas as pdimport numpy as np
パンダをインポートすることをお勧めします pdとして とnumpy npとしての科学図書館 。このアクションにより、 pdを使用できます またはnp コマンドを入力するとき。それ以外の場合は、毎回完全なモジュール名を入力する必要があります。

新しいPython環境を開始するたびに、Pandasライブラリをインポートすることが重要です。
シリーズとデータフレーム
Python Pandasは、SeriesとDataFramesを使用してデータを構造化し、さまざまな分析アクションに備えます。これらの2つのデータ構造は、パンダの多様性のバックボーンです。リレーショナルデータベースにすでに精通しているユーザーは、Pandasの基本的な概念とコマンドを本質的に理解しています。
パンダシリーズ
シリーズは、Pandasライブラリ内のオブジェクトを表します。これらは、各データ要素を一意のラベルとペアにすることにより、単純な1次元データセットに構造を与えます。シリーズは2つのアレイで構成されています– main データとインデックスを保持する配列 ペアのラベルを保持する配列。
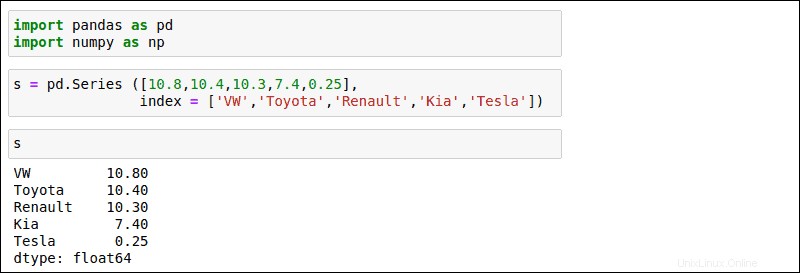
次の例を使用して、基本的なシリーズを作成します。この例では、シリーズはメーカーによって索引付けされた自動車販売番号を構成しています:
s = pd.Series([10.8,10.7,10.3,7.4,0.25],
index = ['VW','Toyota','Renault','KIA','Tesla')
コマンドを実行した後、 sと入力します 作成したシリーズを表示します。結果には、入力された注文に基づいてメーカーが一覧表示されます。
数学関数、データ操作、シリーズ間の算術演算など、シリーズで一連の複雑で多様な関数を実行できます。 Pandasのパラメーター、属性、およびメソッドの包括的なリストは、Pandasの公式ページで入手できます。
パンダデータフレーム
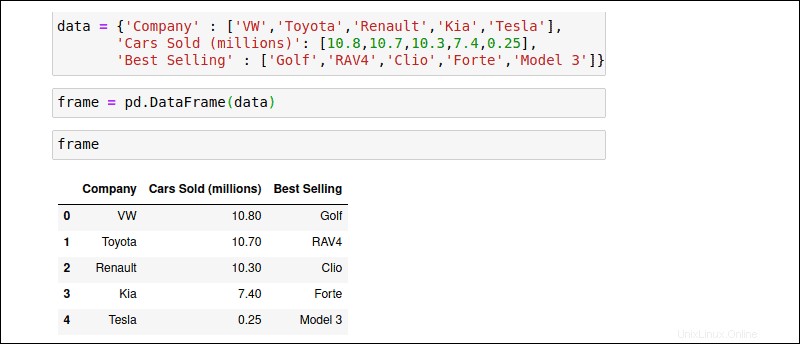
DataFrameは、Seriesデータ構造に新しいディメンションを導入します。インデックス配列に加えて、厳密に配置された列のセットは、DataFrameにテーブルのような構造を提供します。各列には、異なるデータ型を格納できます。 dictを手動で作成してみてください 同じ自動車販売データを持つ「データ」と呼ばれるオブジェクト:
data = { 'Company' : ['VW','Toyota','Renault','KIA','Tesla'],
'Cars Sold (millions)' : [10.8,10.7,10.3,7.4,0.25],
'Best Selling Model' : ['Golf','RAV4','Clio','Forte','Model 3']}
「data」オブジェクトをpd.DataFrame()に渡します コンストラクター:
frame = pd.DataFrame(data)
DataFrameの名前frameを使用します 、オブジェクトを実行するには:
frame結果のDataFrameは、値を行と列にフォーマットします。
DataFrame構造を使用すると、列と行に基づいて値を選択およびフィルタリングし、新しい値を割り当て、データを転置することができます。 Seriesと同様に、Pandasの公式ページには、DataFrameのパラメーター、属性、およびメソッドの完全なリストがあります。
パンダを使った読み書き
Pandasは、SeriesとDataFrameを介して、ユーザーがテキストファイル、複雑なバイナリ形式、およびデータベースに保存されている情報をインポートできるようにする一連の機能を導入しています。 Pandasでデータを読み書きするための構文は簡単です:
-
pd.read_filetype = (filename or path)–他の形式からパンダにデータをインポートします。 -
df.to_filetype = (filename or path)–パンダから他の形式にデータをエクスポートします。
最も一般的な形式には、 CSV が含まれます 、 XLXS 、 JSON 、 HTML、 およびSQL 。
| 読む | 書き込み |
|---|---|
| pd.read_csv(‘filename.csv’) | df.to_csv(「ファイル名またはパス」) |
| pd.read_excel(‘filename.xlsx’) | df.to_excel(「ファイル名またはパス」) |
| pd.read_json(‘filename.json’) | df.to_json(「ファイル名またはパス」) |
| pd.read_html(‘filename.htm’) | df.to_html(「ファイル名またはパス」) |
| pd.read_sql(「テーブル名」) | df.to_sql(「DB名」) |
この例では、 nz_population CSVファイルには、過去10年間のニュージーランドの人口データが含まれています。次のコマンドを使用して、を使用してCSVファイルをPandasライブラリにインポートします。
pop_df = pd.read_csv('nz_population.csv')ユーザーはDataFrameの名前を自由に定義できます( pop_df )。新しく作成されたDataFrameの名前を入力して、データ配列を表示します。
pop_df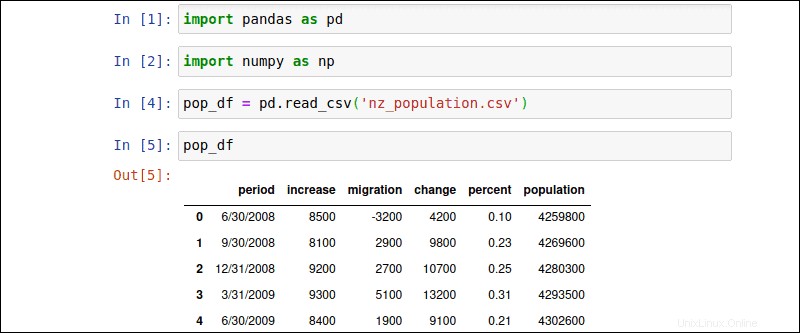
一般的なパンダコマンド
Pandasライブラリにファイルをインポートすると、一連の簡単なコマンドを使用してデータセットを探索および操作できます。
基本的なDataFrameコマンド
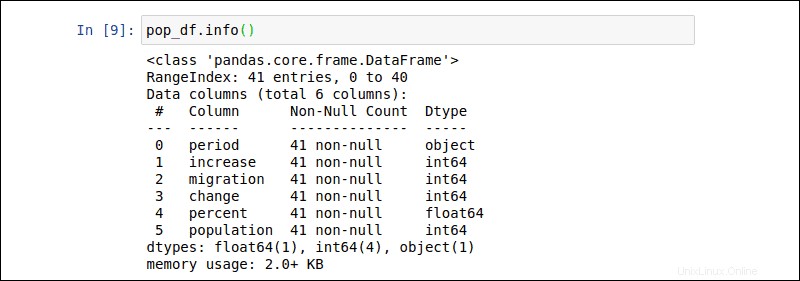
次のコマンドを入力して、 pop_dfの概要を取得します 前の例のDataFrame:
pop_df.info()出力には、エントリの数、各列の名前、データ型、およびファイルサイズが表示されます。
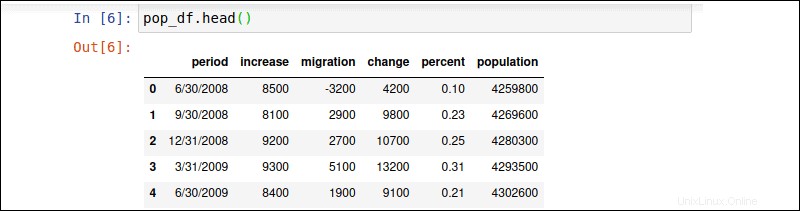
pop_df.head()を使用します DataFrameの最初の5行を表示するコマンド。
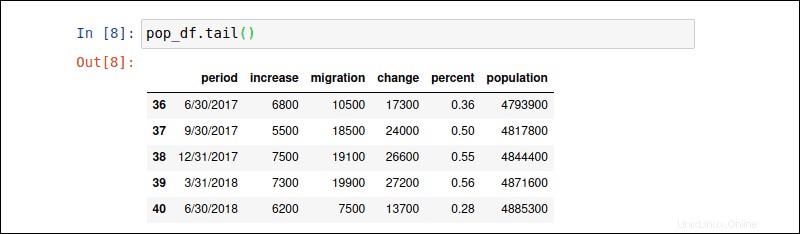
pop_df.tail()と入力します pop_dfの最後の5行を表示するコマンド DataFrame。
名前とilocを使用して、特定の行と列を選択します 属性。角かっこ内の名前を使用して単一の列を選択します:
pop_df['population']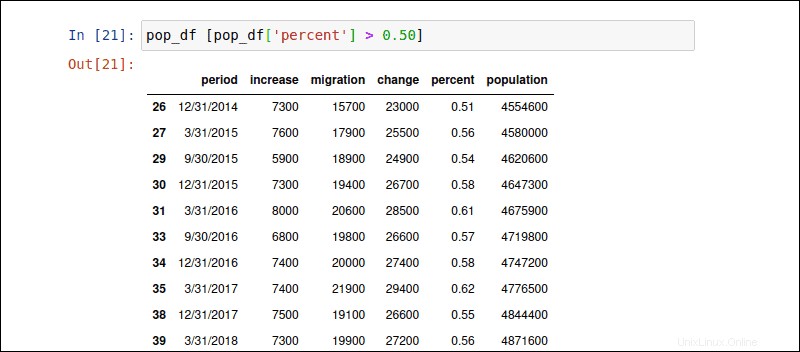
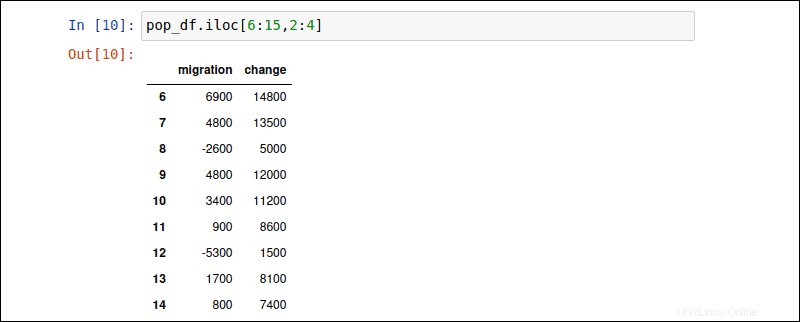
iloc 属性を使用すると、行と列のサブセットを取得できます。行はコンマの前に指定され、列はコンマの後に指定されます。次のコマンドは、行6から16、および列2から4のデータを取得します。
pop_df.iloc [6:15,2:4]
コロン: 指定されたサブセット全体を表示するようにパンダに指示します。
条件式
条件式に基づいて行を選択できます。条件は角括弧[]内で定義されます 。次のコマンドは、「パーセント」列の値が0.50パーセントより大きい行をフィルタリングします。
pop_df [pop_df['percent'] > 0.50]データ集約
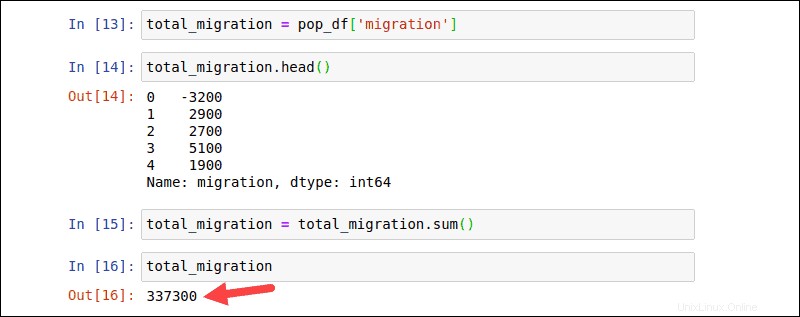
関数を使用して、配列全体から値を計算し、単一の結果を生成します。角かっこ[] また、ユーザーが1つの列を選択して、それをDataFrameに変換できるようにします。次のコマンドは、新しい total_migrationを作成します 移行からのDataFrame pop_dfの列 :
total_migration = pop_df['migration']最初の5行を確認して、データを確認します。
total_migration.head()
df.sum()を使用して、ニュージーランドへの純移住を計算します 機能:
total_migration = total_migration.sum()total_migration出力は、 total_migrationの値の合計を表す単一の結果を生成します DataFrame。
より一般的な集計関数には、次のものがあります。
-
df.mean()–値の平均を計算します。 -
df.median()–値の中央値を計算します。 -
df.describe()–統計の要約を提供します。 -
df.min()/df.max()–データセットの最小値と最大値。 -
df.idxmin()/df.idxmax()–最小および最大のインデックス値。
これらの重要な機能は、Pandasが提供しなければならない利用可能なアクションと操作のごく一部にすぎません。