はじめに
MapReduceは、ApacheHadoopプロジェクトの処理モジュールです。 Hadoopは、コンピューターのネットワークを使用してビッグデータに取り組み、データを保存および処理するために構築されたプラットフォームです。
Hadoopの非常に魅力的な点は、手頃な価格の専用サーバーでクラスターを実行できることです。低コストの消費者向けハードウェアを使用してデータを処理できます。
Hadoopは非常にスケーラブルです。最小1台のマシンから始めて、クラスターを無限の数のサーバーに拡張できます。このソフトウェアライブラリの2つの主要なデフォルトコンポーネントは次のとおりです。
- MapReduce
- HDFS – Hadoop分散ファイルシステム
この記事では、2つのモジュールの最初のモジュールについて説明します。 学ぶ MapReduceとは何か、その仕組み、およびHadoopMapReduceの基本的な用語 。

Hadoop MapReduceとは何ですか?
Hadoop MapReduceのプログラミングモデルは、HDFSに保存されているビッグデータの処理を容易にします。
相互接続された複数のマシンのリソースを使用することで、MapReduceは大量の構造化データと非構造化データを効果的に処理します 。
Sparkやその他の最新のフレームワークが登場する前は、このプラットフォームは分散ビッグデータ処理の分野で唯一のプレーヤーでした。
MapReduceは、Hadoopクラスター内のノード全体にデータのフラグメントを割り当てます。目標は、データセットをチャンクに分割し、アルゴリズムを使用してそれらのチャンクを同時に処理することです。複数のマシンでの並列処理により、ペタバイト単位のデータでも処理速度が大幅に向上します。
分散データ処理アプリ
このフレームワークにより、分散データ処理用のアプリケーションを作成できます。 HadoopはJavaに基づいているため、通常、Javaはほとんどのプログラマーが使用するものです。 。
ただし、RubyやPythonなどの他の言語でMapReduceアプリを作成することはできます。開発者が使用する言語に関係なく、Hadoopクラスターが実行されているハードウェアについて心配する必要はありません。
スケーラビリティ
Hadoopインフラストラクチャは、エンタープライズグレードのサーバーとコモディティハードウェアを採用できます。 MapReduceの作成者は、スケーラビリティを念頭に置いていました。マシンを追加する場合は、アプリケーションを書き直す必要はありません。クラスターの設定を変更するだけで、MapReduceは中断することなく機能し続けます。
MapReduceを非常に効率的にしているのは、HDFSと同じノードで実行されることです。 スケジューラー データがすでに存在するノードにタスクを割り当てます。この方法で操作すると、クラスターで利用可能なスループットが向上します。
MapReduceの仕組み
大まかに言えば、MapReduceは入力データをフラグメントに分割し、それらをさまざまなマシンに分散します。
入力フラグメントは、キーと値のペアで構成されます。並列マップタスクは、クラスター内のマシン上のチャンク化されたデータを処理します。マッピング出力は、reduceステージの入力として機能します。削減タスクは、結果を特定のキーと値のペアの出力に結合し、データをHDFSに書き込みます。
Hadoop分散ファイルシステムは通常、MapReduceソフトウェアと同じマシンセットで実行されます。フレームワークがデータも保存しているノードでジョブを実行すると、タスクを完了する時間が大幅に短縮されます。
HadoopMapReduceの基本的な用語
前述したように、MapReduceはHadoop環境の処理レイヤーです。 MapReduceは、ジョブに関連するタスクで機能します。アイデアは、1つの大きなリクエストを小さな単位にスライスすることで、それに取り組むことです。
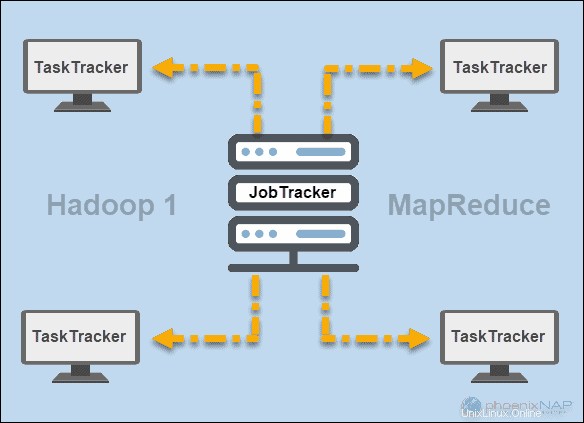
JobTrackerとTaskTracker
Hadoop(バージョン1)の初期には、 JobTracker およびTaskTracker デーモンはMapReduceで操作を実行しました。当時、HadoopクラスターはMapReduceアプリケーションしかサポートできませんでした。
JobTracker クラスタ内のコンピューティングリソースへのアプリケーション要求の分散を制御しました。 MapReduceの実行とステータスを監視したため、マスターノードに常駐していました。
TaskTracker JobTrackerからのリクエストを処理しました。すべてのタスクトラッカーは、Hadoopクラスター内のスレーブノード全体に分散されていました。
YARN
その後、Hadoopバージョン2以降で、YARNがメインのリソースおよびスケジューリングマネージャーになりました。 そのため、さらに別のリソースマネージャーという名前が付けられました。 。 Yarnは、Hadoopクラスターでの分散処理のために他のフレームワークとも連携しました。
MapReduceジョブ
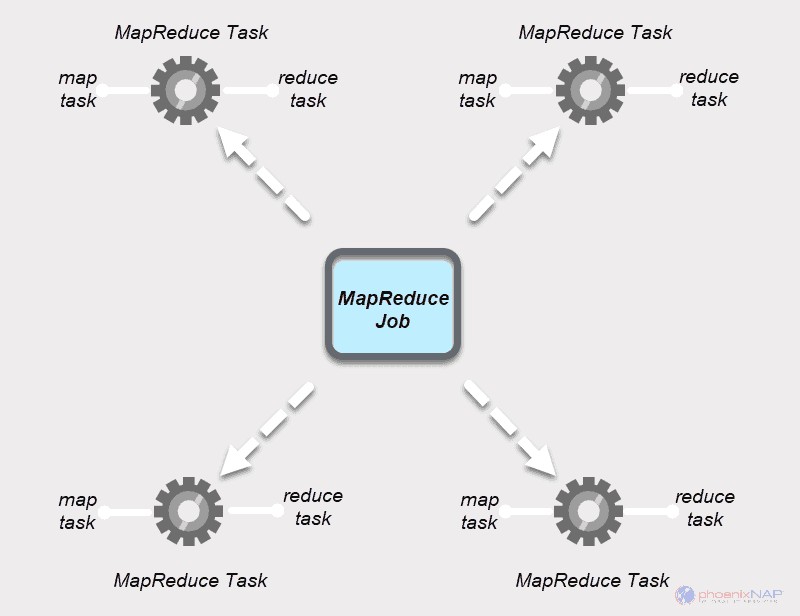
MapReduceジョブ MapReduceプロセスの最上位の作業単位です。これは、MapおよびReduceプロセスが完了する必要のある割り当てです。実行を高速化するために、ジョブはマシンのクラスター上で小さなタスクに分割されます。
タスクは、タスク処理時間を正当化するのに十分な大きさである必要があります。ジョブを非常に小さなセグメントに分割する場合、分割の準備とタスクの作成にかかる合計時間は、実際のジョブ出力を生成するために必要な時間よりも長くなる可能性があります。
MapReduceタスク
MapReduceジョブには2種類のタスクがあります。
マップタスク MapReduceアプリの単一インスタンスです。これらのタスクは、データブロックから処理するレコードを決定します。入力データは、Hadoopクラスター内の割り当てられたコンピューティングリソースで並行して分割および分析されます。 MapReduceジョブのこのステップは、reduceステップの
タスクの削減 マップタスクの出力を処理します。マップステージと同様に、すべてのリデュースタスクは同時に発生し、独立して機能します。データは集約および結合されて、目的の出力を提供します。最終的な結果は、MapReduceがデフォルトでHDFSに保存する
MapステージとReduceステージにはそれぞれ2つの部分があります。
地図 パートは最初に分割を扱います 個々のマップタスクに割り当てられる入力データの。次に、マッピング 関数は、中間のキーと値のペアの形式で出力を作成します。
削減 ステージにはシャッフルとリデュースステップがあります。 シャッフル マップ出力を取得し、関連するKey-Value-Listペアのリストを作成します。次に、削減 シャッフルの結果を集約して、MapReduceアプリケーションが要求した最終出力を生成します。
HadoopマップとReduceが連携する方法
名前が示すように、MapReduceは、入力データを2段階で処理することで機能します–マップ および削減 。これを示すために、各ドキュメントでの単語の出現回数を数える簡単な例を使用します。
私たちが探している最終的な出力は次のとおりです。Apache、Hadoop、Class、Trackという単語がすべてのドキュメントに合計で表示される回数 。
説明のために、環境例は3つのノードで構成されています。入力には、クラスター全体に分散された6つのドキュメントが含まれます。ここでは簡単にしておきますが、実際には制限はありません。何千ものサーバーと何十億ものドキュメントを持つことができます。
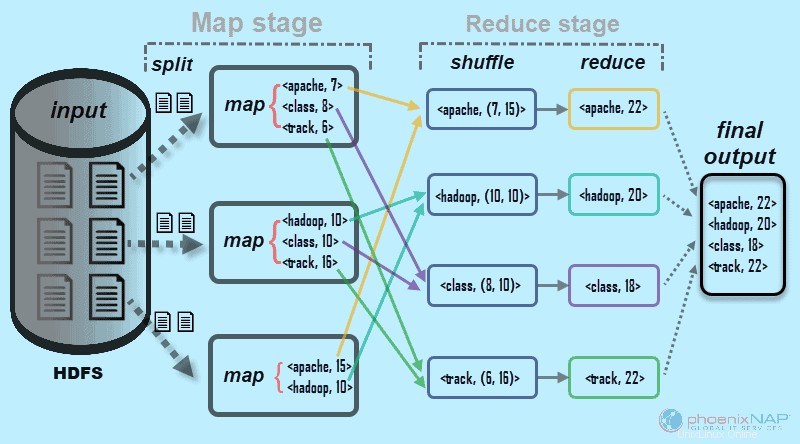
1。 まず、マップ段階 、入力データ(6つのドキュメント)は分割 クラスタ全体(3台のサーバー)に分散されます。この場合、各マップタスクは2つのドキュメントを含む分割で機能します。マッピング中、ノード間の通信はありません。それらは独立して実行されます。
2。 次に、マップタスクは <キー、値>を作成します すべての単語のペア。これらのペアは、単語が出現する回数を示します。単語はキーであり、値はそのカウントです。たとえば、1つのドキュメントには、探している4つの単語のうち3つが含まれています。 Apache 7 時間、クラス 8回、 および追跡 6回。 1つのマップタスク出力のキーと値のペアは次のようになります。
-
- <クラス、8>
- <トラック、6>
このプロセスは、すべてのドキュメントのすべてのノードで並列タスクで実行され、一意の出力を提供します。
3。 入力の分割とマッピングが完了すると、すべてのマップタスクの出力がシャッフルされます。 。これは、削減ステージの最初のステップです。 。 4つの単語の出現頻度を探しているので、4つの並列Reduceタスクがあります。リデュースタスクは、マップタスクと同じノードで実行することも、他のノードで実行することもできます。
シャッフルステップ キーを確実にApache、Hadoop、Class、 および追跡 削減ステップのためにソートされます。このプロセスでは、値をキーごとに
4。 削減ステップ Reduceステージでは、4つのタスクのそれぞれが
図の例では、reduceタスクは次の個別の結果を取得します。
-
-
- <クラス、18>
- <トラック、22>
5。 最後に、Reduceステージのデータ 1つの出力にグループ化されます。 MapReduceは、 Apache、Hadoop、Class、という単語の回数を表示するようになりました。 および追跡 すべての文書に登場しました。集約データは、デフォルトでHDFSに保存されます。
ここで使用した例は基本的なものです。 MapReduceは、はるかに複雑なタスクを実行します。
いくつかのユースケースは次のとおりです。
- Apacheログをタブ区切り値(TSV)に変換します。
- ブログデータ内の一意のIPアドレスの数を決定します。
- 複雑な統計モデリングと分析を実行します。
- Mahoutなどのさまざまなフレームワークを使用して機械学習アルゴリズムを実行する。
Hadoopパーティションが入力データをマッピングする方法
パーティショナーは、マップ出力の処理を担当します。 MapReduceがデータをチャンクに分割し、それらをマップタスクに割り当てると、フレームワークはKey-Valueデータを分割します。このプロセスは、最終的なマッパータスクの出力が生成される前に実行されます。
MapReduceはパーティションを作成し、キーに基づいて出力を並べ替えます。ここでは、個々のキーのすべての値がグループ化され、パーティショナーは各キーに関連付けられた値を含むリストを作成します。単一のキーのすべての値を同じレデューサーに送信することにより、パーティショナーはマップ出力をレデューサーに均等に分散することを保証します。
デフォルトのパーティショナーは多くのユースケースに合わせて適切に構成されていますが、MapReduceがデータをパーティション分割する方法を再構成できます。
カスタムパーティショナーを使用する場合は、すべてのレデューサー用に準備されるデータのサイズがほぼ同じであることを確認してください。データを不均等に分割すると、1つのreduceタスクの完了にはるかに長い時間がかかる可能性があります。これにより、MapReduceジョブ全体の速度が低下します。